
TEE - 数据安全新范式¶
Laisky Cai
本次分享主要想介绍一下基于硬件的机密计算 TEE 领域,这很可能代表着下一个时代的标准安全基座。
因为 TEE 相关的第一课,这次主要是相关概念和方法论介绍,不会有具体实现,不需要相关背景知识。
本 slide 的在线浏览地址:https://s3.laisky.com/public/slides/TEE-101.slides.html

What is CC/TEE¶
Confidential Computing(CC) is the protection of data in use using hardware-based Trusted Execution Environments (TEE).
一般将基于硬件实现的可信执行环境(TEE)称为机密计算(CC)。
What is TEE¶
A trusted execution environment (TEE) is a secure area of a main processor. It helps code and data loaded inside be protected with respect to confidentiality and integrity.
可信执行环境(TEE)是一种旨在为处理器上运行的数据提供机密性和完整性的保障。
What is integrity¶
data integrity means maintaining and assuring the accuracy and completeness of data over its entire lifecycle. This means that data cannot be modified in an unauthorized or undetected manner.
数据完整性指的是在数据的整个生命周期(lifecycle)中,都不会被恶意篡改。
我们这里对数据采用广义的定义,即包括程序代码(算子)和处理及传输的数据。
Measure¶
确保数据完整的方式,就称为“度量(Measurement)”,一般来说最常见的度量方式,就是计算比对数据的哈希摘要,如 SHA-256。
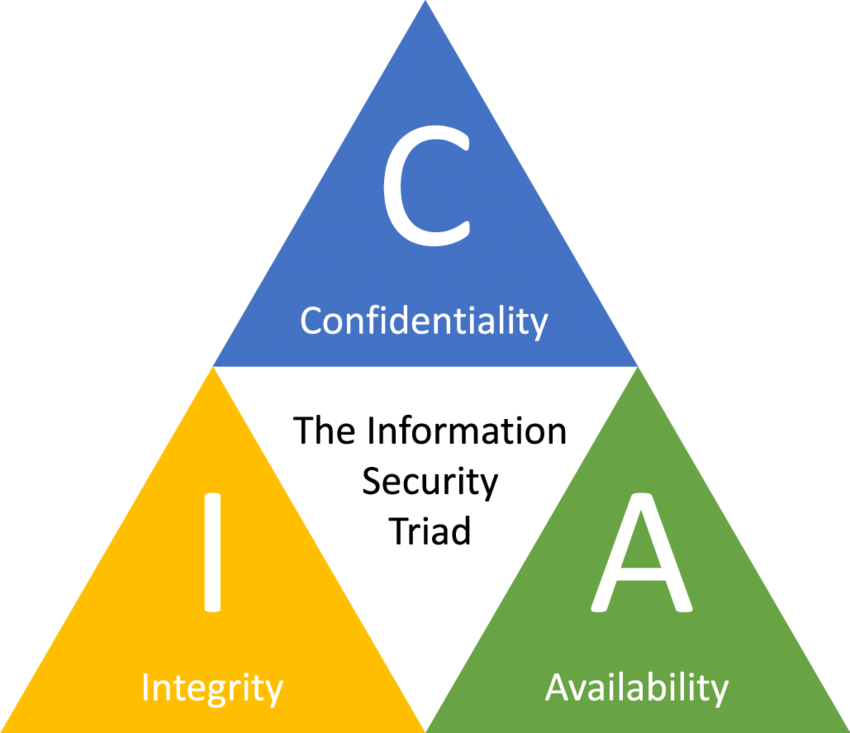
CIA Traid¶
既然提到了完整性,就不能不提到设计一个安全系统时,不得不考虑的 CIA 不可能三角。
在数据的完整生命周期中,同时保有如下三个特性的成本是非常高昂的,往往只能三者取其二。
Integrity & Confidentiality & Availability
一般来说 Integrity 是必要的,主要是在 Confidentiality 和 Availability 间做权衡。
通俗地理解:越安全的就越难用,越好用的就越不安全。
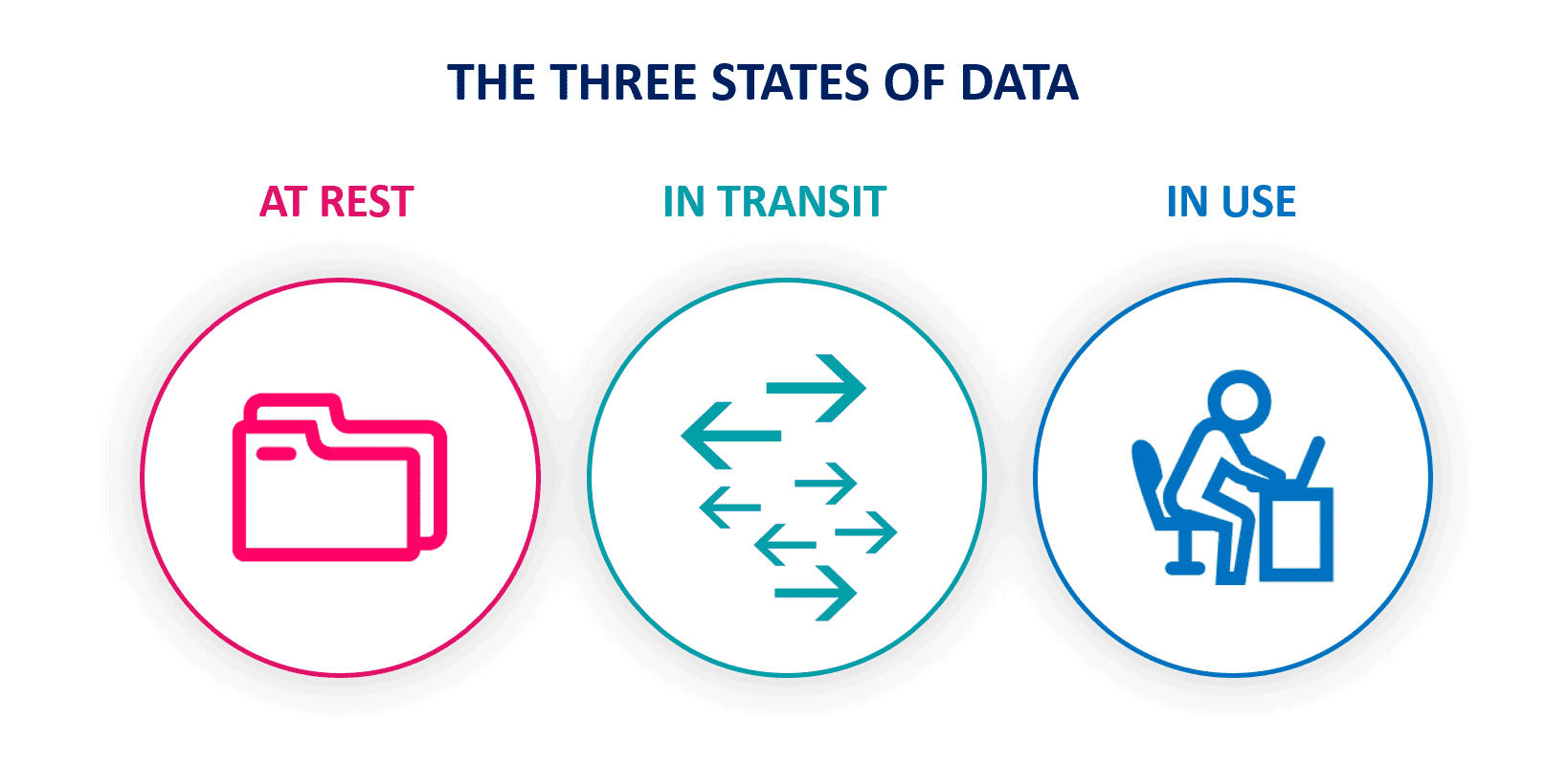
What is Data Lifecycle¶
前文多次提到数据生命周期。在安全领域,根据不同的防护设计理念,一般将数据的生命周期拆分为三个阶段:
at-rest: 数据的存储安全in-transit: 数据的传输安全in-use: 数据的运行时安全
要介绍这三者的差异,就需要介绍为什么我们需要 TEE 了(WHY)
数据处理环境的变化:云时代¶
 |
过去,人们在自己维护的物理机器上运行程序。 物理机器、网络基础设施、操作系统和程序都是自己管理的, 主要的风险暴露面是外部网络或第三方程序。 |
对于第三方程序,我们可以只从可信的发布者那里获取程序,并且小心地度量程序的完整性。
对于无法确认可信的程序,我们可以在虚拟机或沙箱(sandbox)中运行,以隔离其对物理机的影响。
对于外部网络,我们可以小心地设置网络程序,尽量避免漏洞, 同时设置防火墙,限制网络访问,以及使用加密协议,避免数据在公网上传输时被窃取。
进入云时代以后,人们延续了过去的做法:小心翼翼地管理好自己的应用程序, 并且设置复杂的防火墙和安全组。
以前做过的事情,我们在云上都做到了, 甚至配合云上各类功能强大的 SaaS,看上去武器库更加丰富了,但这样真的就足够保护数据安全了吗?
从数据生命周期来分析:
at-rest: 通过 AES-XTS 等方式对持久化数据加密in-transit: 通过 TLS 对数据传输进行加密in-use: ❓
很容易看出,在过去,人们对 in-use 运行时安全的防护是比较欠缺的。
毕竟机器和操作系统都在我们自己的手中,除了内贼外很难被外人窥探。
但是进入云时代后,最大的变化就是物理机器和操作系统都不再完全仅处于我们的掌握之中了。
云厂商(CSP, Cloud Service Provider)控制着物理机器、宿主机操作系统和虚拟机操作系统。
你其实只是虚拟机操作系统上的一个特权用户而已。
虚拟机上的一切数据,对于虚拟机操作系统、宿主机操作系统而言,都形同明文。
数据流通的变化:新法规¶
在互联网的野蛮生长阶段,对数据隐私的保护是很漠视的,基本上只要任何双方谈妥了,就可以进行数据交换。
但是随着世界各国数据安全法的出炉,数据的跨境、跨域(法人域)流通的渠道逐步被法规堵死。 如今甚至连同一个集团下的各个分公司数据,都不能轻易地再进行汇聚。
注:这个双方指的是数据的拥有方和数据的使用方。在 CC 时代,还会出现算力提供方和平台提供方。
不仅仅是法规要求,随着大数据时代和 AI 大模型时代的相继到来,数据的价值日益凸显,各个数据源对核心数据的保护也日益重视。
这就为数据的隐私流通提出了新的挑战和机遇,这也是过去几年 MPC、FL、HE 等隐私计算算法蓬勃发展的根本动力。
隐私数据流通的场景¶
考虑到可能有对隐私计算不了解的同学,这里通过两个简单的例子,来试图形象地说明需要数据隐私流通的场景。
从数据流通的角度来说,主要就两种场景:
- 你需要数据,如何使用他人的数据?
- 你拥有数据,如何将数据给他人使用?
再提炼一下,其实是同一个核心需求:如何在不共享原始明文数据的前提下,实现数据价值
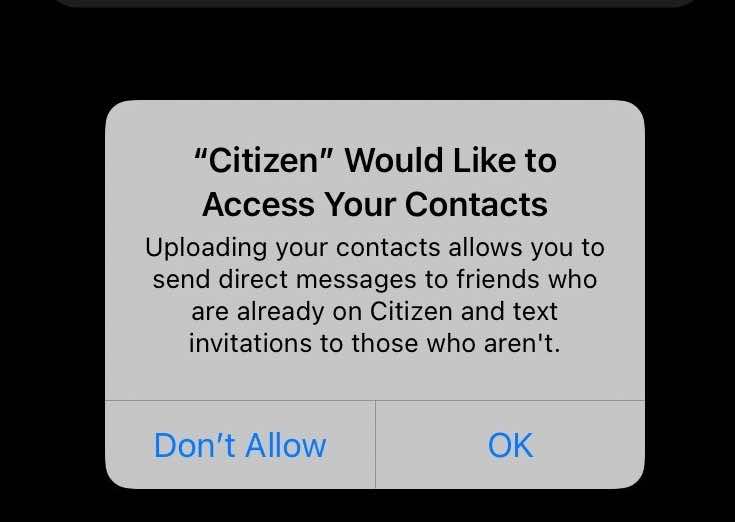
你确实希望 App 给你推荐你通讯录内的好友,但是你不希望上传自己的通讯录。
隐私计算的目的,正是实现这类数据可用不可见的需求。
机密计算 TEE,则是在基于算法的隐私计算之外,提出了一条基于硬件的新的解决途径。
TEE 和传统隐私计算相比最大的差异在于:
- 高性能,媲美原生应用
- 易用性,支持通用计算
我个人认为,TEE 的实用路径比隐私计算还要更宽一些。 TEE 不仅能解决隐私计算试图解决的数据共享问题,更是解决了数据全生命周期安全的问题。

What is TEE¶
这一章我会试图简要地介绍 TEE 的相关概念和方法论,不会做太细节的分析。
开放隐私计算论坛曾经推过这本书,我没抽到免费赠书,自己去买了一本来看,还是挺有意思的。 一些机密计算、隐私计算的历史沿革书里有很详细的介绍,我这里就不赘述了。


沙盒有时候又称为 SFI, Software-based Fault Isolation,顾名思义,这是一种依赖于软件实现的隔离技术。
一般都依赖于操作系统内核提供的一系列功能来实现,如 cgroup、selinux 等,我们可以称 docker 就是一种沙盒。
但是的一般认为基于软件的 TEE 不如基于硬件的 TEE 安全,这就需要介绍下如何大致地估量一个安全系统的安全性。
RoT¶
信任根(RoT, Root of Trust),是一个安全系统的根基,是一个安全系统的最小可信计算单元。
就像是你要证明一个数理系统以前,首先需要确立一系列的公理,这些公理是不需要证明的,你需要无条件的相信它们。
RoT 就是安全系统里的公理,是你无条件相信的最小可信计算单元。 当我们评估一个安全系统的设计的时候,首先要考虑的就是这个系统的 RoT 是什么,可信度怎么样。

TCB¶
可信计算基(TCB, Trusted Computing Base),是指实现的这个安全系统中,你需要相信的所有计算单元。是 RoT 的超集。
习惯上用 TCB 指代你围绕 RoT 所构建的整个安全系统本身,包含各类固件、软件等。 TCB 也是一个安全系统的重要指标,一旦 TCB 出现任何漏洞,整个安全系统的可信度都会受到影响。
所以一般认为,TCB 越小的系统,安全性也就越高。
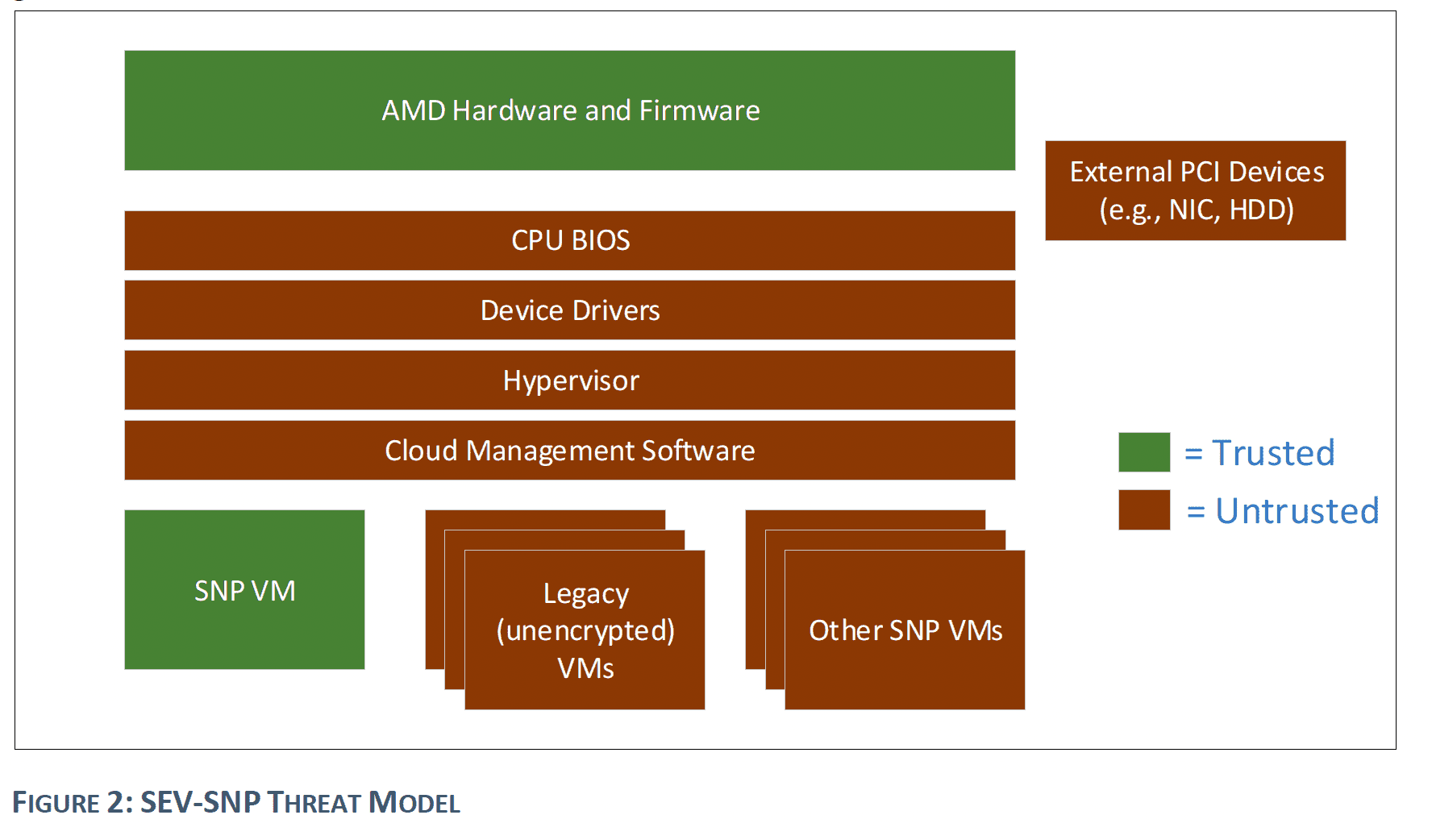
Threat Modeling¶
分析一个系统的安全性的这种系统性分析方法,就称为威胁建模(Threat Modeling)。
最常见的方法,就是绘制出整个系统的实现设计图,从最底层的 RoT 开始,绘制出 TCB 的每一个组成部分,然后从内部和外部的攻击者的角度,分析每一个组件的安全性。
这是 docker 的威胁模型示意,画出架构图,并列举所有的威胁面
软件 TEE 的安全性依赖于操作系统,仅能防范应用由内至外的攻击,对于由外至内,如来自操作系统向应用的攻击,软件 TEE 无能为力。
换句话说,沙盒技术更多的用来保护平台不被应用攻击,而很难保护应用不被平台攻击。

Hardware-based RoT¶
鉴于软件 TEE 的脆弱性,目前人们更多的依赖于硬件 TEE。
为了获取尽可能小的 TCB 和尽可能少的暴露面,我们需要将 RoT 放在硬件层面,即硬件信任根(hardware-based RoT)
无论是 AMD、ARM 还是 Intel 的硬件 TEE 实现,其核心理念是一致的。
在 CPU 上实现数据隔离和加密,软件通过和 CPU 的指令交互,来实现对敏感数据的加解密和访问。 软件的完整性和机密性都通过 CPU 硬件/固件 来保证,从而实现了一个硬件信任根,尽可能地减少了 TCB 的大小。
这些方案主要的区别,主要在于 TCB 的粒度:
- 进程级:Intel SGX、ARM TrustZone
- 虚拟机级:AMD SEV、Intel TDX、ARM CCA
后文中,主要选择 Intel SGX 和 AMD SEV 进行简要介绍,这两者正好各自作为进程级和虚拟机级硬件 TEE 的代表。
本次分享主要涉及通识概念,不会深入介绍细节,之后可能会有其他老师会具体介绍一些实现方案。
TEE 四要素¶
无论如何实现,TEE 一般都应该实现如下几个通用功能:
- verifiable launch and remote attestation: 可信启动与远程证明
- runtime isolation / memory curtaining: 运行时隔离
- trusted I/O: 端到端加密、特权设备等
- secure storage / sealing: 持久化数据加解密
arXiv:2205.12742v1 - SoK: Hardware-supported Trusted Execution Environments
用更通俗的话来表述,TEE 硬件应该能够提供如下功能
- 加载软件时,对软件进行度量,并能够向远程校验者(verifier)提供硬件签名的证明报告(QUOTE/REPORT),证明 TEE 硬件的有效性和软件的完整性。
- 通过隔离和加密,保护数据运行时安全(
in-use) - 能够让 TEE 内的软件和外部设备间建立可信的通信(
in-transit) - 提供基于软件度量值的硬件派生密钥,让软件可以对数据进行加密持久化(
at-rest)
SP & tamper-proof NVRAM¶
一般来说,大部分硬件安全设备,最核心的部分都是一个加密处理器(SP, secure processor)和一个防破坏的非易失性存储器(tamper-proof NVRAM)。
SP 提供密钥生成、密钥派生、加解密等计算功能,NVRAM 提供持久化存储功能。而且这个 NVRAM 是具有防御物理攻击的能力的, 比如能够检测到外部的物理攻击,或者在物理攻击发生后,能够自动擦除数据。
TEE 的硬件芯片也是这样,无论是 Intel 还是 AMD 的 CPU,出厂前,都会在 CPU 的 NVRAM 里生成一个硬件私钥, 然后设备制造商给这个私钥签发一个证书,这个证书就是设备的唯一标识。
而且这个证书就将 CPU 日后签发的证书和设备制造商的 RootCA 关联起来, 日后你可以用设备制造商的 RootCA 来校验 CPU 签发的证书的合法性。
RA-TLS¶
在远程证明(remote attestation)这个场景下,我们将运行于 TEE 内的程序称为 tester,将外部的校验者称为 verifier。
一般来说 tester 拥有算力,而 verifier 拥有数据。
verifier 信任某种 TEE 技术的安全性,也信任某个程序的行为。 他愿意将自己的数据传输给运行于 TEE 之中的某个程序,并且确认这个程序不会泄露自己的数据。
所以,tester 需要向 verifier 证明 TEE 环境的真实有效性以及自己程序的完整性。
这一证明流程,就称为远程证明(remote attestation)。
前面提到,TEE 在加载执行软件时,会对其进行度量,并记录软件的度量值(一般是 SHA-256)。
TEE 硬件也会提供接口,让 TEE 程序可以生成一个由硬件私钥签名的报告(REPORT/QUOTE),这个报告会包含 TEE 环境和 tester 软件的度量值。
verifier 通过设备制造商的 RootCA 就可以校验这份 Report 的真实性,然后就可以确认 TEE 环境的真实有效性和 tester 软件的完整性。
为了防止 reply attack,生成报告时会允许注入一段限定长度的用户数据(chanllenge/nonce)。
这个数据也会被 tester 添加到报告里并且一起被硬件签名,这样 verifier 就可以确认这个报告是实时生成的。
// 一个伪代码的接口示意
func GetReport(userData []byte) Report
根据上述特性,人们找到了一种在 verifier 和 tester 间建立 TLS 端对端加密通信的方法。
verifier as Server¶
如果 tester 是服务端,那么 tester 可以在 TEE 内启动后,生成一对公私钥和数字证书,然后用这个数字证书创建一个 TLS 服务端接口。
因为私钥是在 TEE 的内存里生成,其安全性得到了保证。
接下来就是需要向 tester 证明,这个私钥确实是由 TEE 程序所持有的。 这就需要利用 RA 流程来进行。
当 verifier 发送一个 nonce 要求生成证书时,tester 可以通过如下方式生成证书
// 将 verifier 发送的 nonce 拼接 tester 的 TLS 证书,取哈希后,生成一个证书
report = GetReport(SHA256(cert + nonce))
verifier 可以执行相同的操作,将 tls peer certificate 和自己发送的 nonce 拼接后再校验报告。
如果校验成功,说明当前的 tls 确实是和 TEE 内的 tester 建立了端对端的加密通信,从而杜绝了中间人攻击。
这其中的几个要点在于:
- tester 的公私钥和数字证书一定要在 TEE 环境内动态生成,通过 TEE 保护其机密性
- tester 的证书摘要也要放进 REPORT,从而利用 RA 流程证明了证书的有效性
- tester 和 verifier 间需要建立 tls 直连,不能在网关层进行 tls 卸载
因为是利用 RA 来实现 TLS,所以这一流程也被称为 RA-TLS。
但是需要注意的是,RA-TLS 和传统 TLS 并不完全兼容:
- 传统 TLS,客户端利用预先准备好的 RootCA 先校验对端证书,再建立 TLS 连接。
- 而 RA-TLS,是先建立 TLS 连接,然后再用 Report 校验对端证书。
对证书的校验从先验变成了后验,你需要先 skip 证书校验建立 TLS 连接,然后再手动去校验 tls conn 的 peer 证书。
verifier as client¶
再来看看 RA-TLS 中 TEE 应用作为客户端的流程:
- tester 在 TEE 内动态生成一对公私钥和数字证书
- 使用证书作为 client certificate 向服务端发起 TLS 连接
- 客户端发送 REPORT,服务端校验 REPORT 和客户端证书,将该连接标记为可信
可以看出,客户端模式采用的是 mTLS 流程,即客户端证书的方式去建立端到端加密通信。而且和服务端模式一样,对客户端证书也得采用后验的模式。
Sealing¶
前文已经介绍了 TEE 实现数据 in-use 和 in-transit 安全,接下来介绍一下数据 at-rest 安全。
TEE 的硬件芯片都会提供密钥派生(key derive)的功能,可以根据软件度量值,从硬件根密钥派生出一个 Sealing Key。
TEE 应用可以将这个 Sealing Key 用于对称加密,从而实现数据 at-rest 安全。
因为 TEE 硬件的根密钥不会变,只要软件的度量值没有变,那么 Sealing Key 就不会变,这样就可以保证数据的可解密性。
Fragility / Brittleness¶
基于 Sealing Key 做持久化加密存在一个问题,就是这个密钥和软件的度量值是绑定的,一旦软件升级,度量值就会变,密钥也会变,从而导致无法解密旧数据。
所以主流的硬件密钥派生接口,一般都会提供两种不同的派生方式:
- 基于软件度量值进行派生
- 基于软件的公钥进行派生
软件开发商(ISV, Independent Software Vendor)可以用自己的私钥为 TEE 软件进行签名,然后将签名和公钥一起打包进 TEE 软件。 TEE 硬件可以通过公钥派生 Sealing Key。
这样,可以实现让持有相同公钥的不同软件,都可以派生出相同的密钥,从而实现加密数据的共享。
Sealing Key 的派生密钥除了受到软件度量值和 ISV 公钥的影响,还受到了硬件根密钥的影响, 这使得 Sealing Key 实际上是绑定到生成它的 CPU 的。
一旦应用换了个 CPU 运行,那么 Sealing Key 就会跟着变,从而导致无法解密旧数据。
(所以在云时代使用 TEE 是需要上层 PaaS 框架支持的)
Ps. 在同一台物理机上切换不同 CPU 是不会导致 sealing key 变化的,只有切换物理机时才会导致发生变化。
拿 intel SGX 来说,如果一个主板上有多个 CPU(Socket),那么 BIOS 会为这些 CPU 协商出一个共享的 platform key 作为根密钥, 从而让多个 CPU 的行为表现得和一个 CPU 完全一致。
这在 Intel 上称为 MPA(Multi- Package Registration Agent)。
对于 Sealing Key 绑定到物理机的情况,要想支持云原生时代的 scalability。 没有简单的解决办法,目前只能通过上层 PaaS 框架的设计,来实现密钥分发和迁移功能。
就如同前文提到的 CIA 不可能三角。这里其实就是 availability 和 confidentiality 之间的权衡。
- 选 confidentiality:密钥完全不出域,安全性极高,但牺牲了可用性,机器一坏就完蛋
- 选 availability:密钥出域,牺牲了安全性,但是可以承受机器损坏
密钥出域不是说直接把加密用的密钥导出 TEE 环境,这样做就完全破坏了 TEE 的机密性。
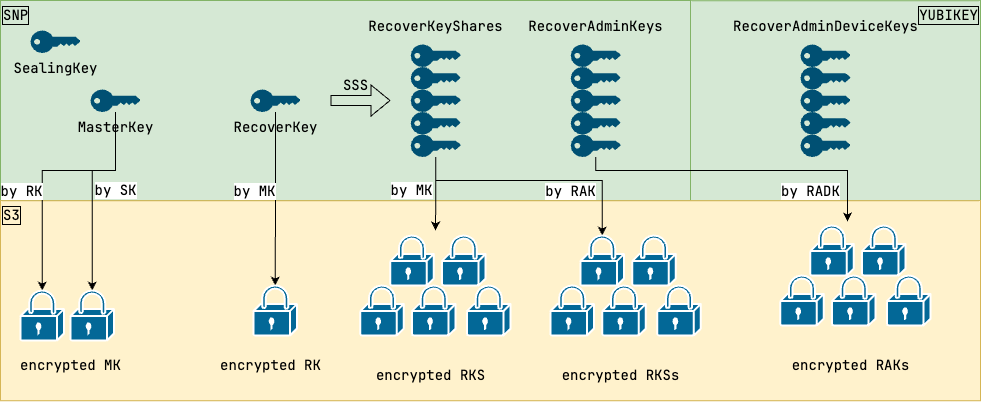
任何端对端加密系统,要想保证可用性,一定会有一个 Recover Key。这个 RK 保证了即使硬件密钥丢失,但是你仍然能恢复原始数据。
至于 recover key、sealing key 和真实加密数据所用的 master key 间是个什么样的映射和派生关系,这就见仁见智,各有各的实现了。
这是我目前主导的一个零信任 TEE 项目的密钥设计图,既让服务器能够基于 sealing key 自动恢复, 也让管理员可以在机器坏掉时手动恢复,还确保了没有任何管理员可以绕过系统,独立解密数据,同时不存在任何可导出的明文密码。
具体细节就不展开了
进程级的 TEE: SGX¶
![]()
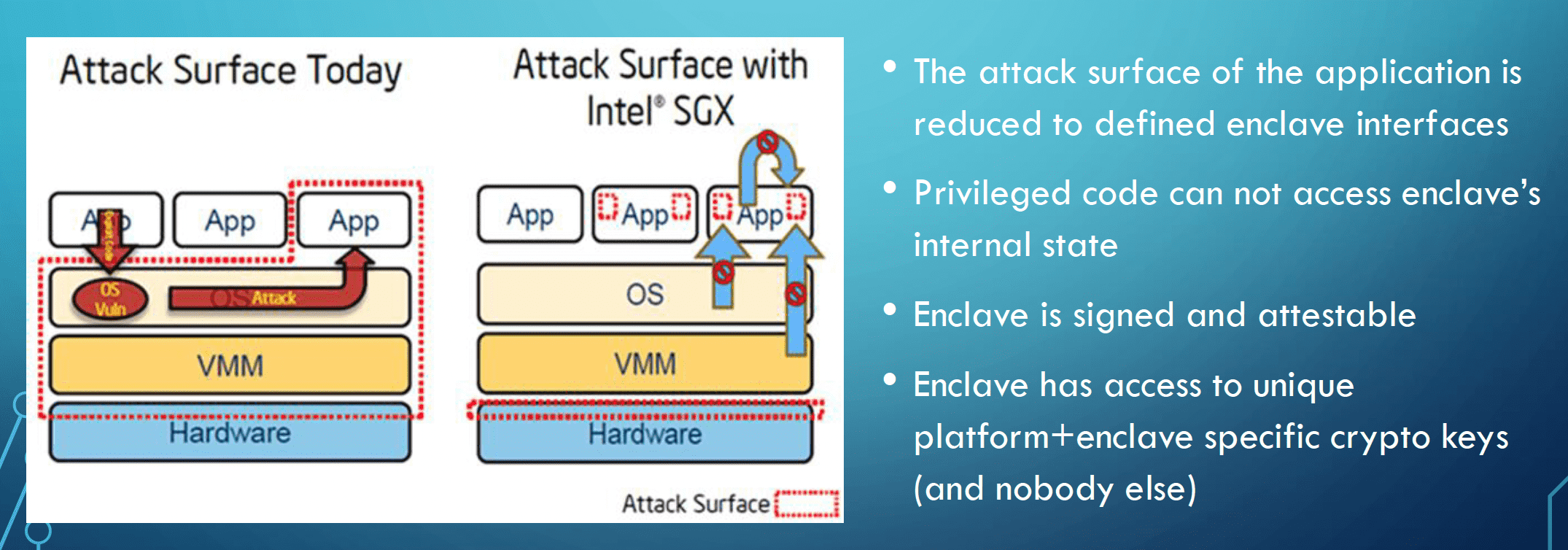
SGX 是 Intel 于 2015 年左右推出的进程级硬件 TEE 技术,其核心理念是:
- 为 SGX 编写的程序称为 Enclave,CPU 保证其完整性和机密性
- BIOS 启动时,将物理内存分为普通内存和 EPC 内存。EPC 内存由 CPU 加密,仅允许 Enclave 应用访问属于自己的 EPC 内存页。
- Enclave 通过实现定义好的 EDL 接口文件和外界交互,外部任何系统或特权用户都无法访问 Enclave 的数据。
最小的 TCB 和暴露面¶
SGX 的困境¶
虽然 SGX 拥有最小的 TCB 为其带来了极高的安全性,但是这是以牺牲易用性为代价换来的。
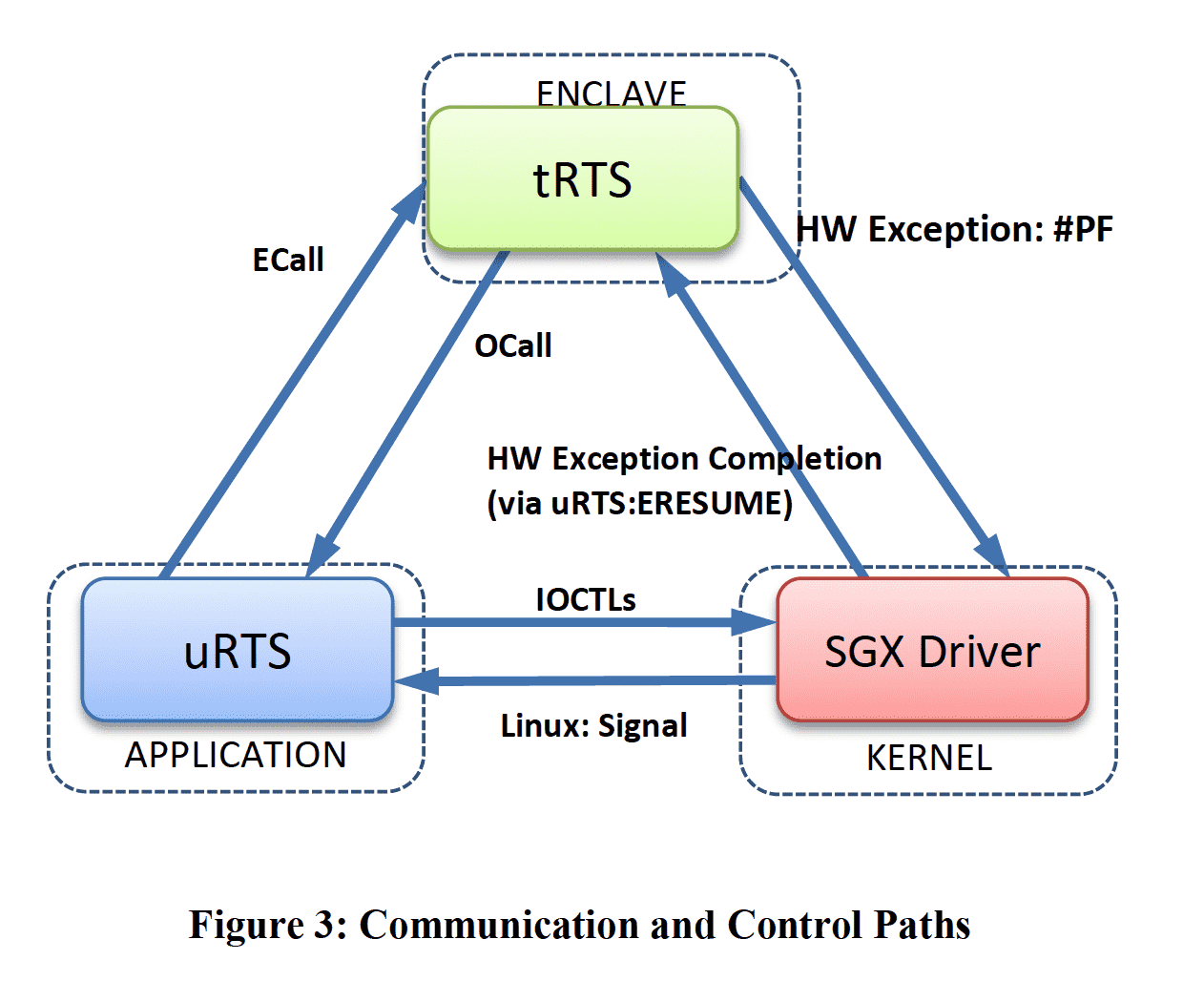
SGX 将软件程序拆分为两部分:
- 运行于加密环境之中的 Trust Runtimes(tRTS)
- 运行于普通 OS 之中的 Untrusted Runtimes(uRTS)
tRTS 作为被严密保护的部分,只能调用 CPU 进行纯计算,唯一能调用的外部接口就是 EDL 文件定义的 OCall/ECall。
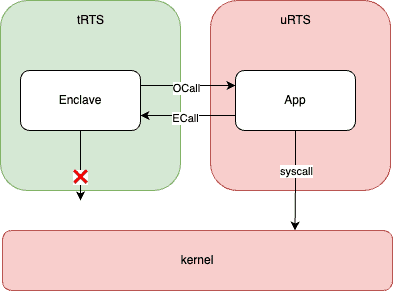
Enclave 要想调用 OS 提供的功能,就必须通过 OCall 调用 uRTS,然后 uRTS 再调用 OS。 uRTS 拿到 OS 的返回值后,再通过 ECall 将结果返回给 tRTS。
uRTS 就扮演了一个代理的角色,不仅可以做转发,还可以做审计和过滤,以提高安全性。
syscall¶
简要介绍一下 system call(简称 syscall)。
为了更好的支持权限管理,CPU 提供了 RING 0 ~ 3 四个不同的保护域,不同域有不同的指令执行权限。 这也被称为分级保护域,Hierarchical Protection Domains。
Linux 只使用了其中的两个态,OS 运行于 Ring 0(有时候也称为 CPL-0),拥有操作设备的权限。 用户程序运行于 Ring 3(CPL-3),仅有使用 CPU 进行计算的权限。
我们也习惯将其称之为 用户/内核 态。

用户态的应用程序没有操作设备指令的权限,那么当这些程序需要调用底层设备的时候(如读写文件、网络 I/O 等)怎么办呢?
此时就由操作系统提供一系列封装好的接口,用户可以通过 CPU 提供的指令将控制权交给内核, 内核提权后根据用户的需要去调用执行相应的 syscall 函数,执行完成后再通过 CPU 指令降权, 控制权交回用户态。
但是实际上用户程序一般并不会直接和 kernel 交互(因为除了 syscall 外,还有大量其他相关工作), 这些“幕后的相关工作”,一般由 libc 来完成。
不过需要注意的是,并不是所有的应用程序都会通过 libc 去发起系统调用, 毕竟如果高级语言支持汇编的话,那也是可以直接发起 CPU 指令的。
就目前来说,用户程序和 kernel 的边界究竟是 syscall 还是 libc 尚无定论。
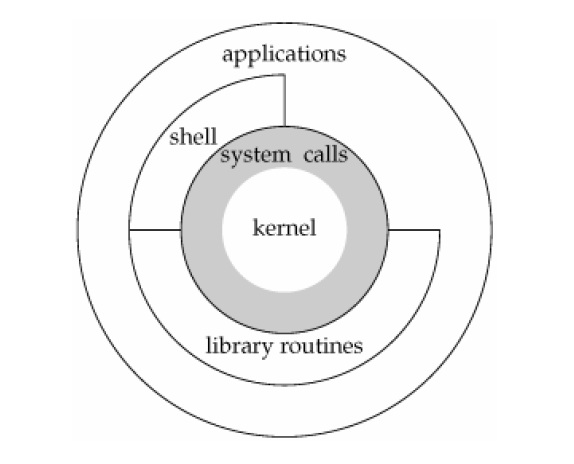
Library OS¶
以 syscall 隔离开 user 和 kernel,导致了大量的上下文切换和数据拷贝开销。
最早的 LibOS 正是一种试验性的探索方向,试图简化 kernel 的职责, kernel 只负责最基础的硬件保护, 而将对设备的操作直接放到用户态里,以 library 的形式提供给应用程序。 应用程序可以在用户态直接调用 libOS。
但是该领域随着 VMM 的崛起而被人遗忘。

VMM 有时候也称为 hypervisor,根据其是运行于 Host OS 之上还是 Bare Metal 之上可以区分为两个类型

简而言之,最早的 VMM 就是试图用用户进程运行一整个操作系统。这有很大的难度,原因之一就是对指令权限的控制非常繁琐和困难。
后来各家芯片厂商提出了硬件虚拟化方案,Intel-VMX(或叫 VT-x)和 AMD-V。
VMX 为 CPU 新增了两种状态:root/non-root。 和原有的 user/kernel 组合后可得四种状态:
- root/user: Intel VMM 运行于用户态
- root/kernel: Intel VMM 运行于内核态
- non-root/user: VM 运行于用户态
- non-root/kernel: VM 运行于内核态(guest OS)
硬件支持 VMM 对 Ring0 的虚拟化操作。
可以设定让 VM CPU 在遇到指定指令时触发 VM EXIT, 将控制权切换给 VMM,从而得以实现对任意指令的拦截。
让 VM 完全意识不到自己运行于虚拟环境之中,有时候也被称为 blue pill。
一句话总结就是,硬件虚拟化极大地降低了 VMM 的实现难度,也提高了 VM 的性能。
再回过头来看 LibOS,实际上它和 VM 的分野也不是那么的清晰。
共同点:都是将 App 封装于一个独立的“沙箱”中
不同点:
- VM 会提供一个完整的 OS,仍然有 user/kernel 的权限区别
- LibOS 完全运行于用户空间,提供部分 OS 的功能
双方也并没有那么泾渭分明,可以笼统地将 libos 认为是轻量级的 VM。
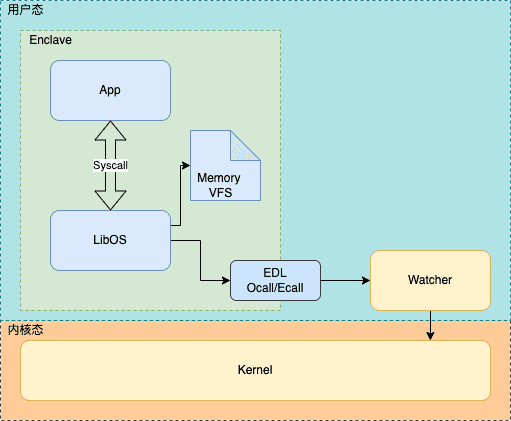
LibOS 在 SGX 领域的应用¶
前文提到 Enclave 没有调用 syscall 的能力,都得重新修改代码,改为通过 EDL 接口转发,这样对用户的开发成本实在过于高昂。
所以人们将目光投向了 LibOS,这种在用户态实现 OS 的方式,正好可以和 Enclave 内的代码无缝对接。 这样实际上就把 Enclave 内的程序又拆分成了两部分:
- App 业务代码,运行于 LibOS 之上,无需改动
- LibOS 底座,负责劫持 App 的所有系统调用,转发给 uRTS
一顿操作猛如虎后,最终架构就成了这样
trap and emulate¶
这里补充一下基础知识,如果 App 代码无需改动,直接发起 syscall,那么 LibOS 是如何拦截到用户的 syscall 的?
在这种应用场景下,libos 的能力基础,全都建立于于对应用程序 syscall 的拦截上。
这种拦截并模拟 syscall 的操作,也称为 Trap And Emulate。
主流的应用程序,大多都是靠 libc 来调用 syscall,而且都能够编译为动态链接到 libc 的可执行程序。
即使是 python 脚本,它也能够通过一个动态链接到 libc 的解释器来执行。
➜ bin git:(master) ldd python
linux-vdso.so.1 (0x00007ffca03f4000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007f09cf57b000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f09cf576000)
libutil.so.1 => /lib/x86_64-linux-gnu/libutil.so.1 (0x00007f09cf571000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f09cf48a000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f09cec00000)
/lib64/ld-linux-x86-64.so.2 (0x00007f09cf597000)
那么 libos 只需要在装载阶段,将 libc 劫持为自己修改过的兼容 libc API 的库就行了。 然后在这些自定义的 libc 兼容库里,对 syscall 想做什么都可以。
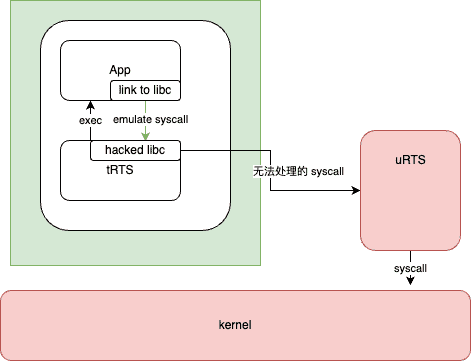
但是前文我们提到,application 和 kernel 的边界并不明确,并不是所有的程序都会调用 LibC。
比如 Golang 就不会调用 libc,而是直接发起 syscall 指令。 目前看到的 LibC 最常见做法是,改 Go 的源码,让它用 libc …

拦截后能做什么?¶
最直接的好处是,即使 libos 什么也不做,仅仅是转发 syscall 给 kernel, 也让 enclave 程序拥有了 syscall 的能力, 这就让 enclave 程序可以读写文件,可以通过 socket 发起网络请求, 或者运行网络服务器。
transparent encryption¶
除此之外还可以透明的实现各种安全增益。
比如,通过改写 socket 的 listen, connect, recv, write syscall,可以实现透明 TLS(TTLS),
即在 syscall 这一层对连接启用 TLS 加密,应用程序完全无感知。
类似的,也可以通过改写 file 的 read, write,实现对文件系统的透明加密。
SGX 开源生态¶
目前 SGX 最常用的 LibOS 包括:
- Gramine: 资深老牌 LibOS 项目,syscall 支持最全
- openenclave: MicroSoft 的开源项目,支持多种硬件平台
- Occlum: 蚂蚁的 LibOS,支持多进程
我估计后面会有其他老师深入介绍其中的实现细节和用法,我这里就不展开了。
虚拟机级的 TEE: SEV¶
TEE 的应用场景已经从早年的数据产权保护,转向了更为广阔的通用计算。
面对通用计算的复杂场景需求,以及为了能够给软件开发者实现尽可能低的开发成本。面向 VM 的 TEE 技术显然具有比进程级的 TEE 更大的优势。
AMD 在 2019 年发布了 SEV 技术,这是一种面向 VM 的 TEE 技术。 此后 Intel 也发布了类似的技术,称为 Intel TDX,此外还有 ARM CCA,可以看出 VM 显然是目前 TEE 技术的发展方向。
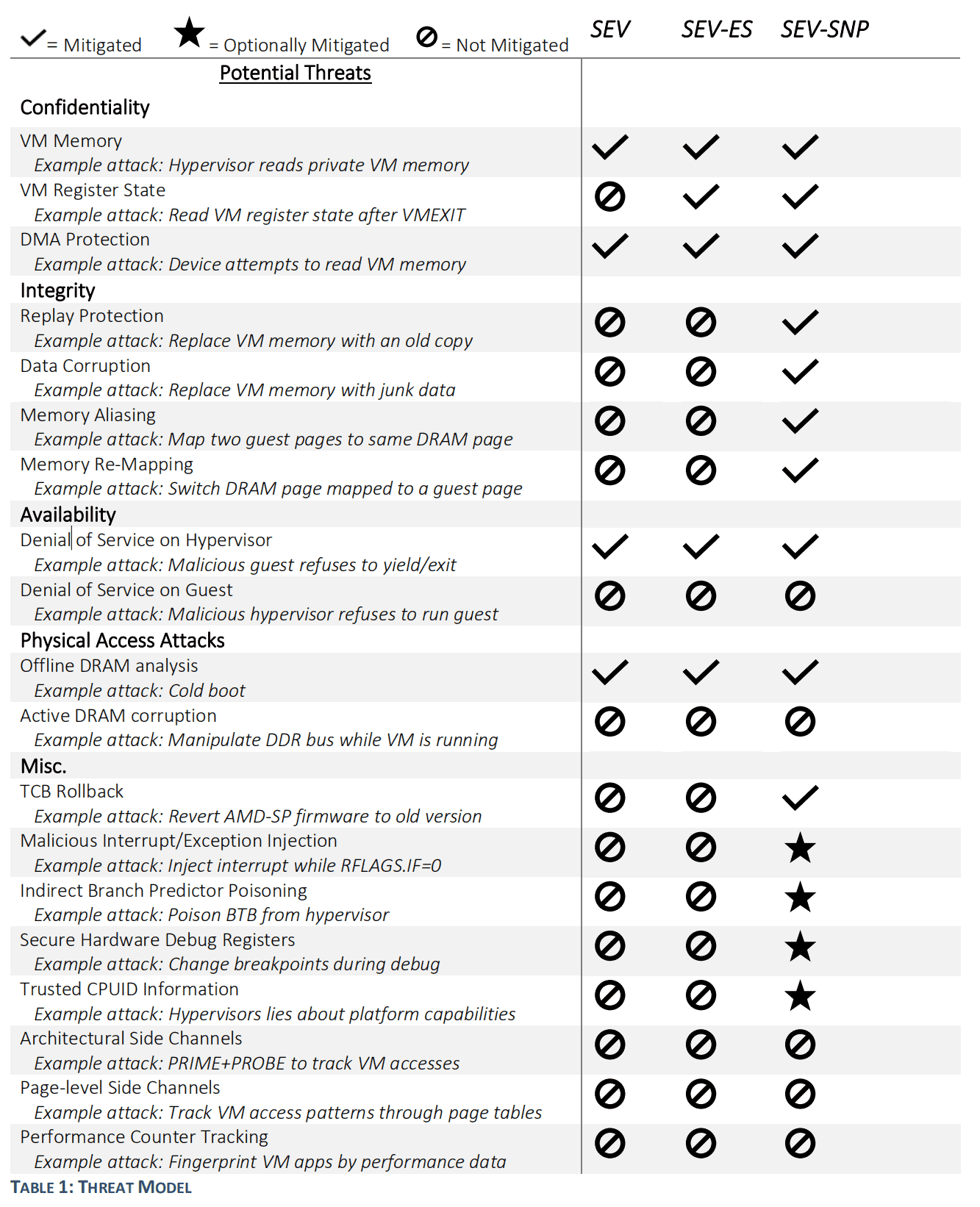
SEV 也经历了三代发展(SEV、SEV-ES、SEV-SNP)

拿 Milan 架构支持的 SNP 来说,其已经具备了前文所述的全部 TEE 四要素。
| SGX | SEV | |
|---|---|---|
| 适用场景 | 通用计算 | 通用计算 |
| 适用范围 | 进程级 | 虚拟机级 |
| RoT | CPU | CPU |
| TCB | CPU | CPU + guest OS |
| 易用性 | 难 | 易 |
| 远程认证 | 支持 | 支持 |
| 基于度量的 Sealing | 支持 | 支持 |
| 基于签名的 Sealing | 支持 | 支持 |
SEV-SNP 和 SGX 最大的区别就在于,TCB 的大小和易用性的权衡。
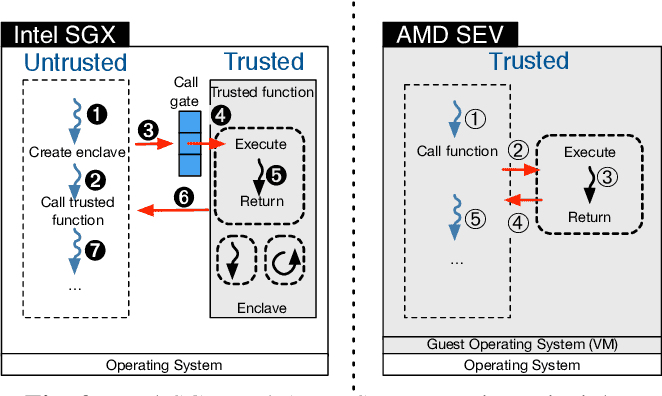
SEV 中,整个 guest os 都是被 trust 的
SME¶
2016 年,AMD 推出了 SME,以实现对内存的透明加密。 同一时间 AMD 也推出了 SEV,这是以 SME 为基础实现的内存加密虚拟机。
SEV 硬件借助 SME,为每一个 CVM 提供一个独立的对称密钥, 对所有内存数据进行加密。 (Intel 上类似技术称为 Intel TMK 和 MKTME)
CVM 需要和外界进行 I/O 通信时,需要使用未加密的 shared memory。
借助 Memory Access Control 技术的思路,利用 GPA 内存地址中称为 C-bit 的一位作为 flag, 标记当前内存页是否需要加密。
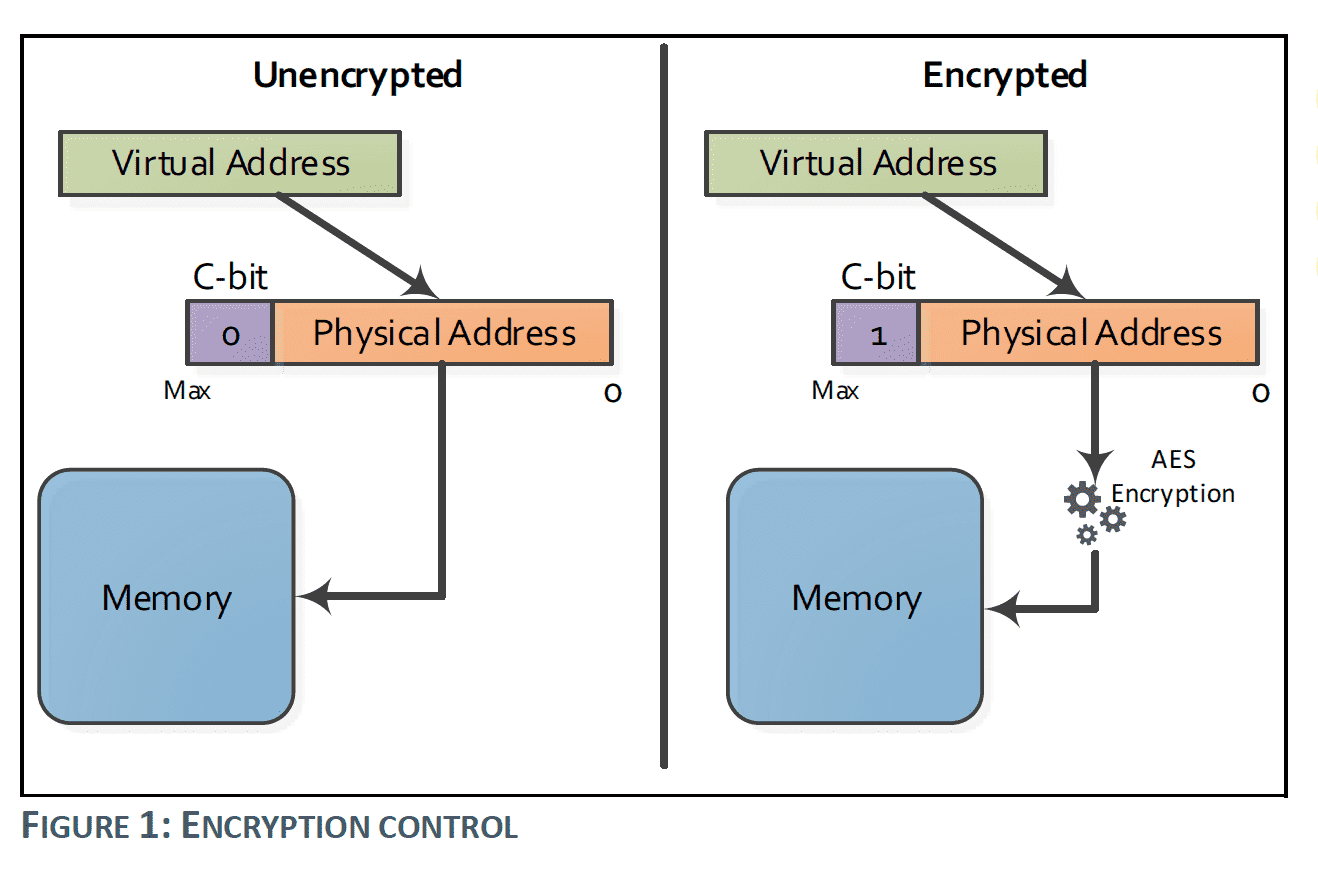

本文中的 SEV 如无特殊说明,都指代最新一代的 SEV-SNP,各代差异此处不具体介绍了
vSGX / HyperEnclave¶
即然提到 AMD SME/SEV 了,稍微跑个题,有个研究方向是基于 AMD SME/SEV 的基础内存加密能力,在上层通过软件(操作系统)构建进程级 TEE。
类似的研究有:
- vSGX- Virtualizing SGX Enclaves on AMD SEV
- 蚂蚁金服的 HyperEnclave
蚂蚁金服基于 AMD SME,通过将 host os (rust monitor)纳入 TCB,来实现进程级 TEE
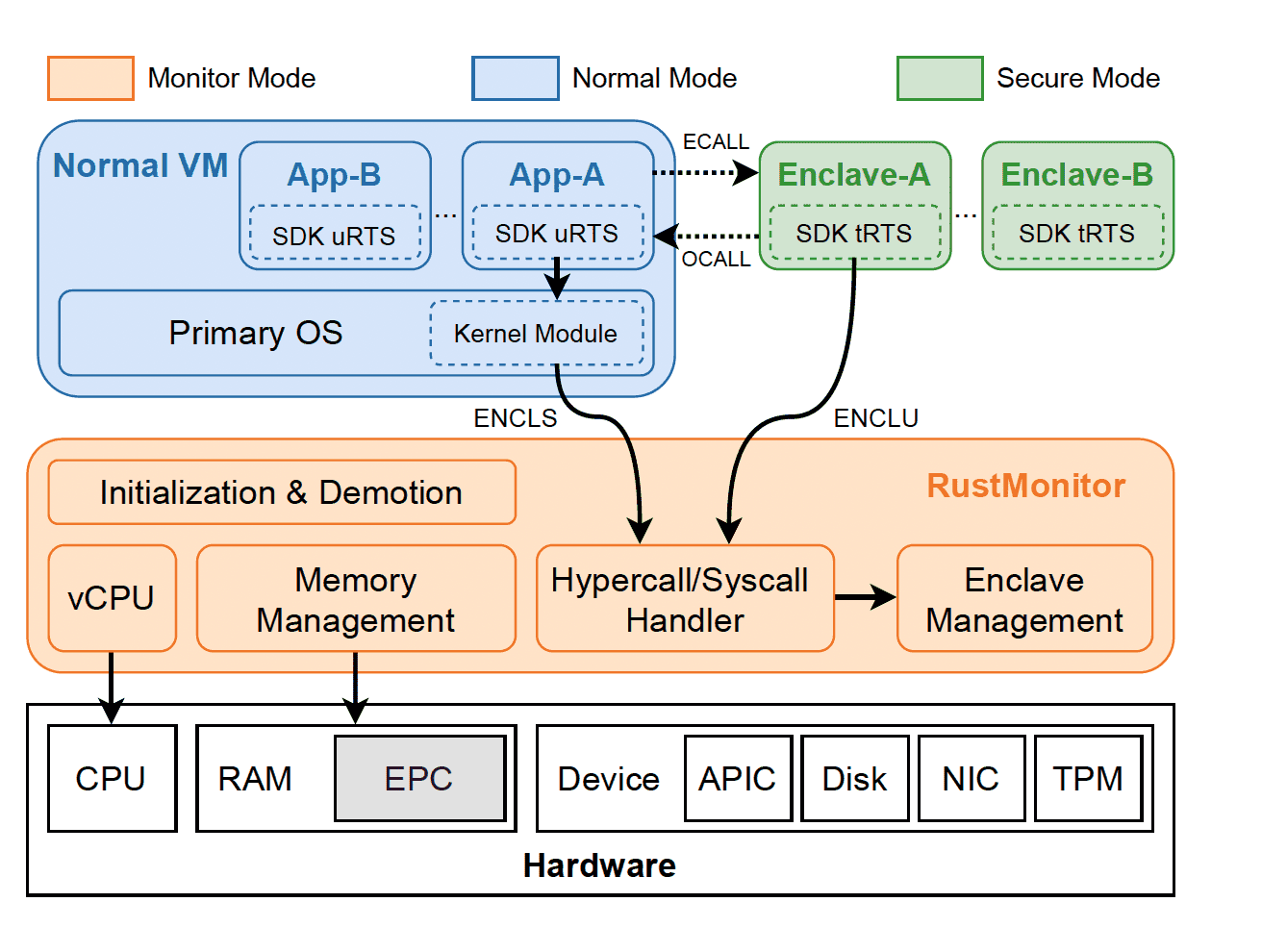
OSU 基于 AMD SEV,构筑进程级 TEE
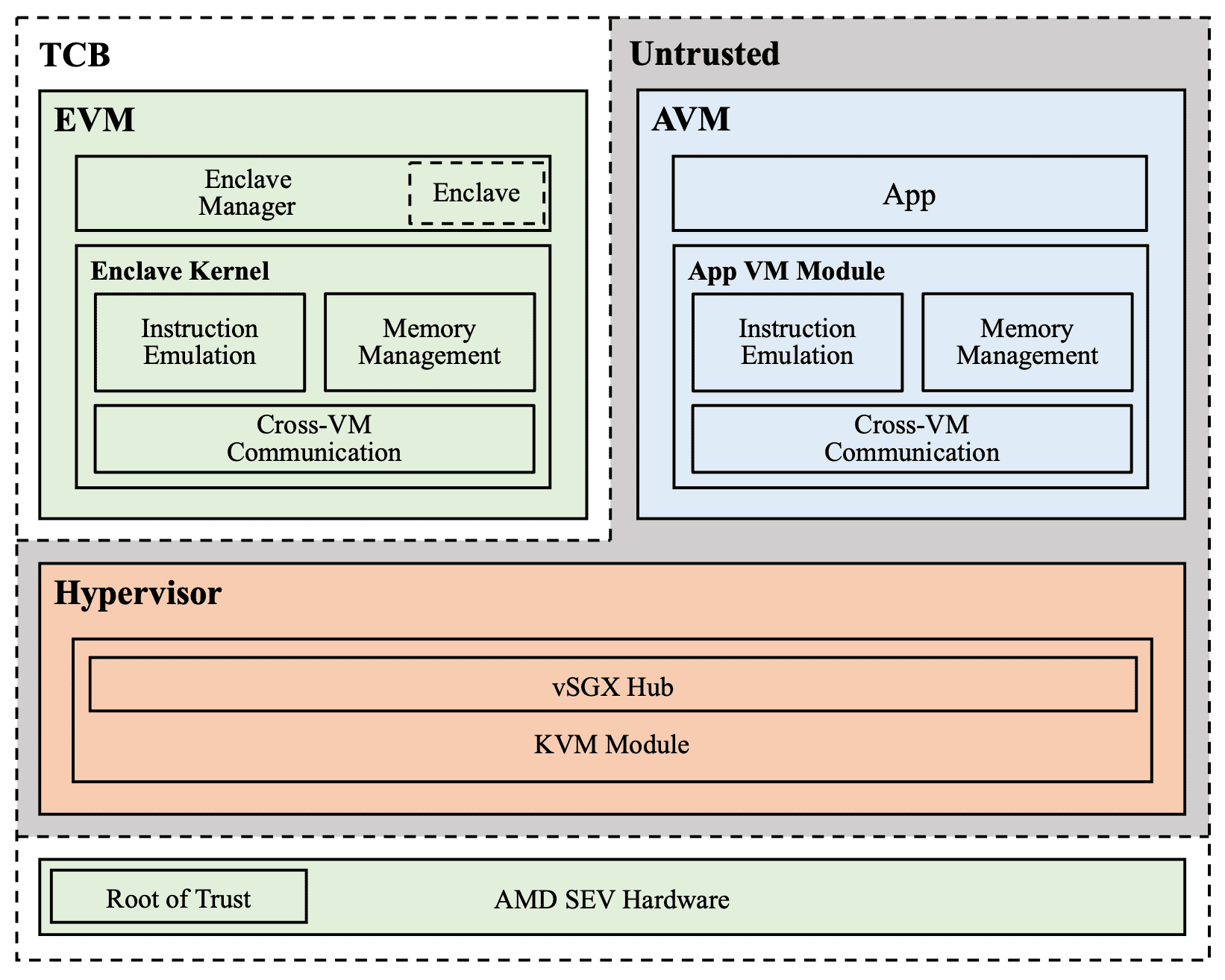
这些 vSGX 方案,本质上就是将之前由 Intel SGX CPU / Intel PSW 实现的功能,转移到了操作系统。 然后将操作系统也纳入 TCB,从而实现了进程级 TEE。
这种做法的优点可能是能够在更廉价的硬件上,实现上层对多种 TEE 方案的兼容。
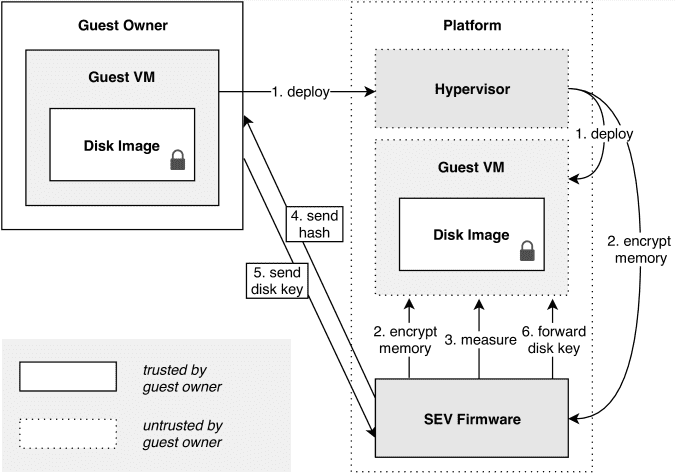
SEV Workflow¶
- 在可信的环境里 build 好 guest os image,生成并记录 guest os 的 measurement
- 将 guest os 部署到具有 SEV-SNP 硬件的机器上
- guest os 启动后自动启动应用程序,程序作为 tester,向外部的 verifier 自证清白
- verifier 对 tester 进行远程认证,验证 SEV-SNP 硬件的真实性和 guest os 的完整性
- 和前文所述相类似的方法,通过 RA-TLS 建立加密通道
进入 64-bit 时代以后,主存的寻址方式变成了 64-bit,而这些 32-bit 的设备无法和主存进行对齐, 使得 DMA 的访问遇到了问题。
这时候出现了 IOMMU(I/O Memory Management Unit) 设备, 这是 AMD-Vi、Intel VT-d、ARM SMMU 等一系列具体实现的统称, 代表一种能够将零散的物理内存映射为一块连续的虚拟地址空间中的设备。
利用 IOMMU 的地址映射支持,就解决了各类外设的地址映射问题。 CPU 可以在一块统一的虚拟地址空间内实现对所有设备内存的访问。
IOMMU 这个名字发源于内存管理模块 MMU(Memory Management Unit), MMU 是 CPU 内部的一个模块,用于将虚拟地址映射为物理地址。 IOMMU 则是用于将外设的物理地址映射为虚拟地址。

不过 IOMMU 最早是由 AMD 提出的,Intel 最早在适配 x86-64 时,并没有采纳 IOMMU 的设计。
Intel 在 2001 年推出它的第一个 x86-64 处理器架构 Itanium 时,采用了一种软件上实现 IOMMU 的做法,
这个软件就称为 SWIOTLB(Software Input Output Translation Lookaside Buffer),
有时候更直白地被称为 SWIOMMU(software IOMMU)。
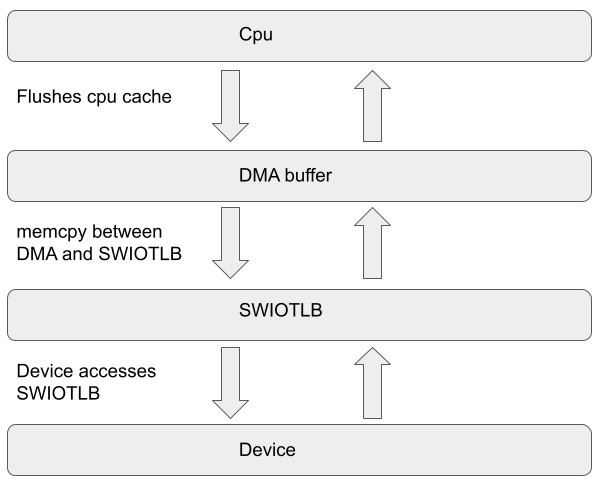
SWIOTLB 的实现方式是,预留一块连续的物理内存区域,作为一个缓冲区,用于存放 I/O 设备的数据。 当 I/O 设备需要访问内存时,先由 CPU 将数据写入 SWIOTLB,然后再由 DMA 将 SWIOTLB 中的数据拷贝到目标设备的内存地址中。
这种方式的缺点是,需要预留额外的内存空间,而且需要 CPU 的参与,性能不高。
随着 32-bit 设备迅速退出历史舞台,IOMMU 和 SWIOTLB 的作用也就不大了。 甚至很多人建议禁用这两个机制,以提高性能。
虚拟化的新机遇¶
随着虚拟化技术的发展,IOMMU 和 SWIOTLB 又重新回到了人们的视野中。 在虚拟环境中,所有内存地址都由虚拟机软件重新映射,这会导致DMA设备失败。IOMMU处理此重新映射,允许在客户操作系统中使用本地设备驱动程序。
从 vmware 的文档看上去,无论是支持 SR-IOV 虚拟化的设备,还是 passthrough 的设备,都需要 IOMMU 的支持。
内存加密时代的新挑战¶
SWIOTLB/SWIOMMU 最初是为了用软件实现 IOMMU 的功能。它会在 OS 启动前,在物理内存上保留一块 32 位寻址的区域(称为 aperture), 一般为 4~64 MB。
每当 DMA 因为地址不匹配而出错时,CPU 就会把数据拷贝到 aperture 内(bounce buffer),然后再让 DMA 传递。
随着 AMD SME、Intel TME 等全局内存加密技术的出现,给 DMA 带来了非常大挑战。
因为主存数据是加密的, DMA 不能再直接将其传输给设备。 于是 AMD 发现 SWIOTLB 指令刚好可以拿来干这事儿。 先将内存解密后放进 SWIOTLB 的 bounce buffer 内,然后再让 DMA 发送给设备。
这张图本来是讲 IOMMU 解决 bounce buffer 问题的, 我们反着来看,bounce buffer 解决了加密内存和未加密的设备间拷贝的问题。
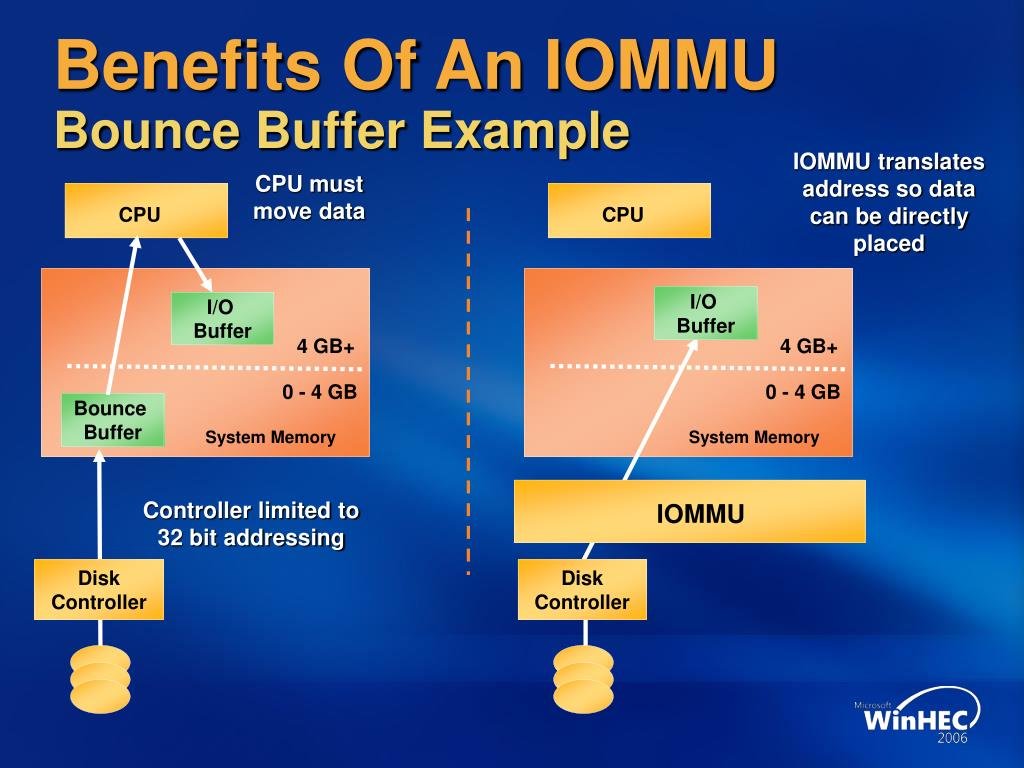
SWIOTLB 是为了低速外设而设计的,它根本无力负担一台 SME/SEV 加密机器全部的 I/O 压力, 很快就会出现 buffer overflow 或者死锁导致 I/O 性能急剧(-80%)下降。
目前 AMD、Intel、Kernel 各家都有各自的解决方案 patch,尝试优化 SWIOTLB 的性能问题。
AMD SEV 官方 Repo 和 GCP CVM 都建议改大 SWIOTLB 来缓解性能问题。
但是光修改 SWIOTLB 大小并不够。Intel TDX 也遇到了完全一样的问题,试图通过优化锁来缓解问题。 Intel TDX 组关于 split swiotlb lock 的 patch 已经进了 6.0 的内核。
- https://github.com/intel/tdx/commit/4529b5784c141782c72ec9bd9a92df2b68cb7d45
- https://github.com/torvalds/linux/commit/20347fca71a387a3751f7bb270062616ddc5317a
阿里也曾提出过另行实现一个动态分配空间的 SWIOTLB 方案。
不过我在 5.19.rc6 的 SNP CVM 上用 iperf 和 dd 简单测了一下网络和磁盘的速度。
看上去和 SNP 宿主机相比,在 1Gbps 的网络下,只有小于 10% 的性能损耗。这一点和 edgeless 公司发布的性能测试结果一致。
不过在大于 5Gbps 时,edgeless 的测试出现了很大的损耗,这一点我尚未验证。
可信计算¶
虽然各家的硬件 TEE 方案,其 TCB 理论上都不包含 host os。
但是基于 host os 特权用户的侧信道攻击(side channel attack)仍然是一个很大的威胁。
而且本着纵深防御的原则,增加对 host os 的防护,也是很有必要的。
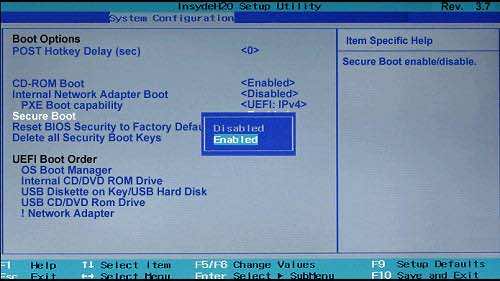
Measured Boot¶
OS 在 secure boot 后被启动,OS 会在之后的启动过程中的数个关键环节, 对每一个关键组件进行校验,确保组件的完整性,这一流程被称为 Measured Boot。

系统如何启动¶
要想确保运行的系统是可信的,需要先了解一下系统的启动过程
- 系统加电加载 BIOS Boot Block
- BIOS/UEFI 开始运行,激活各个协处理器、硬件
- BIOS 执行 kernel loader,加载 OS
- OS 启动后运行 init 进程,该进程按照配置启动各个 App 进程
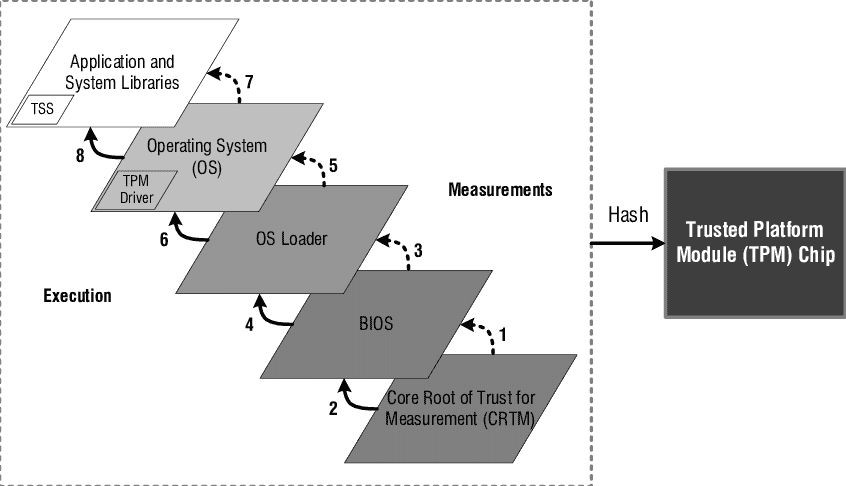
Measurement¶
TPM 中包含了数个只读寄存器,称为 PCRs(Platform Configuration Registers)。
每当系统重启时,所有的 PCR 都会被清空。然后在系统启动过程的不同阶段, 各个 PCR 按照预设的程序会对系统当前的状态进行度量(Measurement), 并且将度量值写入到对应的 PCR 之中。

可以用一段伪代码来描述 tpm 的行为
// TPM PCR 的行为几乎和 hash 函数一模一样
hasher := sha256.New()
<- bootblock.Ready()
hasher.Write(bootblock.Measure())
tpm.SetPCR(1, hasher.Sum(nil))
<- bios.Ready()
hasher.Write(bios.Measure())
tpm.SetPCR(2, hasher.Sum(nil))
<- os.Ready()
hasher.Write(os.Measure())
tpm.SetPCR(3, hasher.Sum(nil))
...
PCR[N] = HASHalg( PCR[N] || ArgumentOfExtend)
TCG PC Client Platform TPM Profile Specification for TPM 2.0.pdf 规范要求 TPM 2.0 硬件应该至少支持 24 个 PCRs, 且支持 SHA256 和 SHA384 算法。

前面提到 PCRs 是只读寄存器,所以在系统启动过程中生成的 PCR 值是不可篡改的。
在制作系统镜像时,我们可以将 PCR 的值记录下来,然后在日后系统启动时进行校验,所有的 PCRs 都不应发生任何变化。
BitLocker¶
顺带一提,Windows BitLocker 就是利用 TPM PCR 来进行磁盘加密。
原理和我们此前提到过的 TEE Sealing Key 如出一辙。利用 TPM 硬件根密钥,由 PCR 值派生出 Sealing Key 对硬件加密。
设计密钥的时候,可以参考一下 bitlocker 的设计思路。
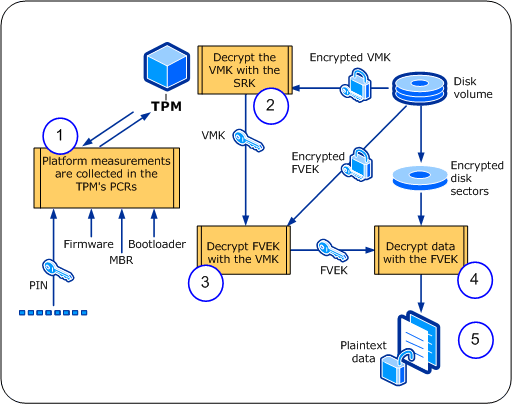
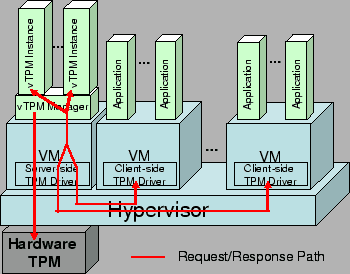
vTPM¶
前文讨论的 TPM 都是插在主板上的硬件模块,这个硬件有一个致命的缺点,就是不支持虚拟化。
为了让虚拟机也能用上 TPM,人们发明了 vTPM。但是这不是常见的硬件虚拟化, 而是在 Host OS 上运行的一个软件,模拟出了 TPM 的设备接口。
在 guest os 内看上去,就和一个拥有物理 TPM 的设备一模一样。
只是这个 TPM 实际上是 host OS 上的一个进程,一般由 VMM 提供。 VMM 会为每一个 VM 维护一个 vTPM 服务实例,每一个实例都会将自己模拟成一个物理 TPM 的设备。
如果 vTPM 进程可靠,那么确实可以如实地度量 VM,VM 也无法篡改 vTPM 的 PCR。
但是这样做其实在无形中扩展了 TCB,你得信任 VMM,才能信任 vTPM。
这是一组常见的 vTPM 架构。TPM 设备 passthrough 进 vTPM server VM 中。
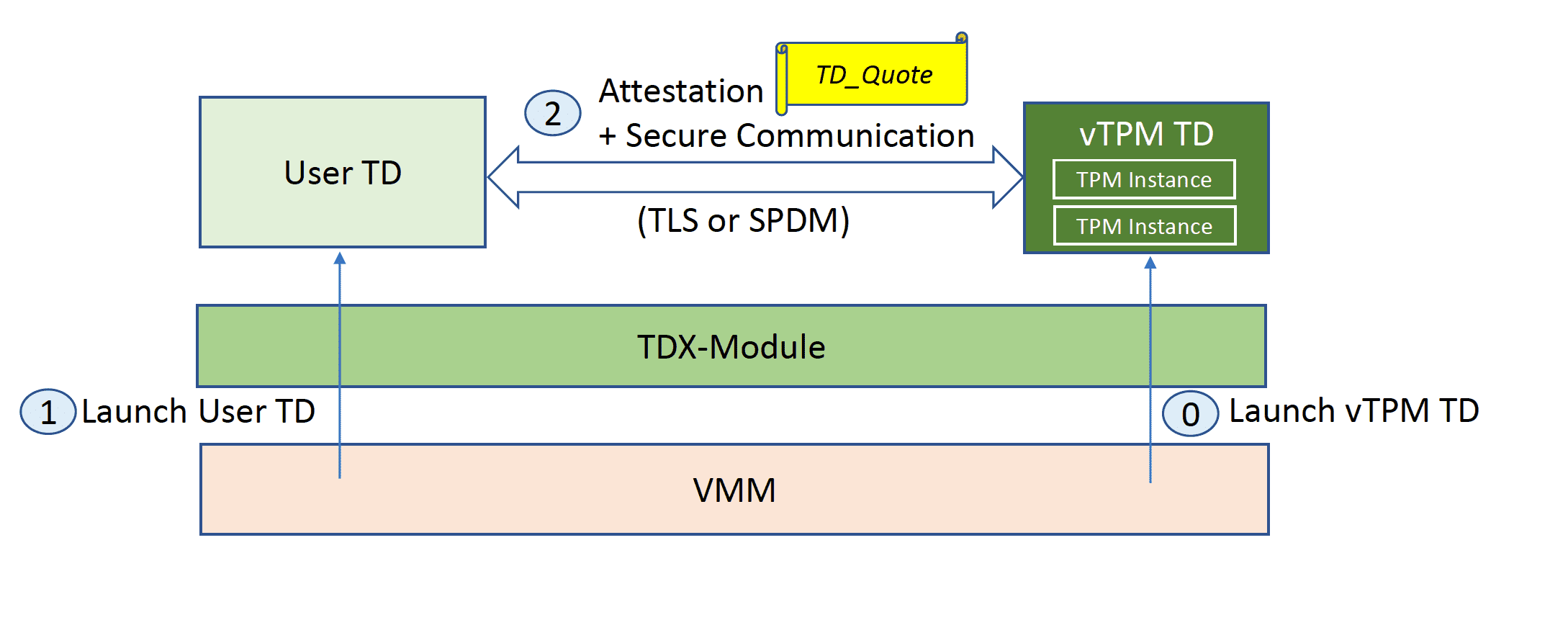
vTPM 与 TEE 的融合¶
前阵子刚开始发售的 intel TDX 在 vTPM 上做了一次很好的改进,它将 vtpm server 也放进 TEE 内运行,然后 vtpm CVM 和 User CVM 间通过本地认证后建立通信,从而在实现 vTPM 功能的同时,将 VMM 排除出了 TCB。
当数据需要离开主存时,有如下几种常见情形:
- 数据持久化:可以通过 Sealing Key 来加密
- 数据传输:可以通过 RA-TLS 加密
- 数据传输到 GPU 等设备:❓❓
可以看出,对外设在机密计算领域还相对薄弱,往往只支持明文数据传输,这对整个 TEE 生态构成了很大的挑战

对其流程进行一个简单的概括:
- User App 运行于 CPU TEE 之中
- TEE 中的 CUDA driver 和 GPU 进行远程认证,然后建立加密信道
- User App 将数据加密传输到 GPU
- GPU 解密后,在 vRAM 内以明文进行运算
可以看出,现阶段外设机密计算,主要加固的还是 in-transit 安全,而 in-use 安全,靠的是将整个 vRAM 纳入 TCB 来实现的。
就是他认为 vRAM 是难以被直接攻破的。

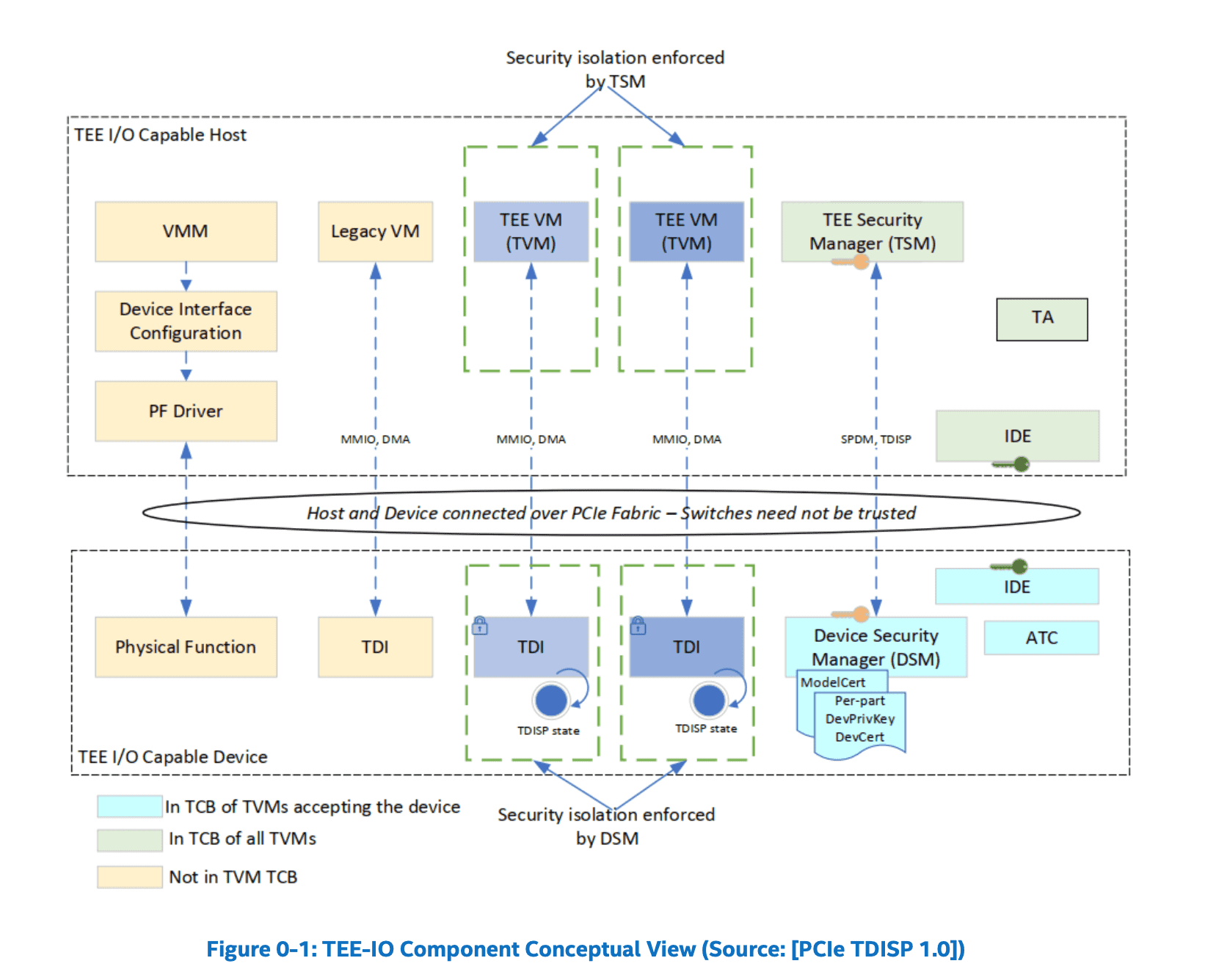
PCIe TDISP¶
既然大家都想要解决外设传输安全,那与其每个硬件各搞一套,不如直接在传输上定制一个统一标准。
于是就有了 PCI-SG 为 PCIe 5.x 制定的 TDISP 标准,专门为 CVM(TDX/SEV)提供 TEE-IO 解决方案。
Software-Hardware-Security Codesign¶
过去的安全范式:安全是被动、滞后的,亡羊补牢型的。
在架构设计上,是首先满足业务需求的前提下,针对安全清单再进行修修补补。
而未来的安全范式是:安全必须成为软件设计的第一等公民。
在设计之初,就必须针对性地以硬件安全能力为基础,去妥善地设计能够利用硬件能力的业务逻辑。 SW-HW-codesign
Zero-Trust Infrastrature¶
2022 年底,密钥管理软件 LastPass 数千万用户密钥被泄漏,引起业界震动。 最后发现是一名高级运维人员的电脑被植入木马,导致权限被盗。
这里就不得不问一个问题,身为敏感用户的拥有者,其实只想用软件服务,为什么需要将数据交给对方?
身为用户,能不能不需要信任服务提供商?
这个问题的答案,也是我认为的未来 TEE 将会大放异彩的一种新的架构形态:零信任基础架构。
无论是 IaaS、PaaS 还是 SaaS 提供方,都可以依托于硬件 TEE 的能力,将自己从 TCB 中移除。
在为用户提供服务的同时,不窥探用户的任何数据。
而且这不是虚无缥缈地口头承诺承诺不窥探,而是通过远程证明、透明度(开源),提供可证明的机密性。
随着机密计算在未来成为云计算的事实标准,可以想见,零信任基础设施也将彻底重塑数据业务的形态。
iOS Advanced Data Protection 号称是端对端加密的,但是它无法证明自己
AWS CloudHSM 声称端对端加密,而且你可以通过 manufacture CA 进行证明,并建立直达设备的 TLS。
这也构成了 AWS 零信任基础设施的 RoT。
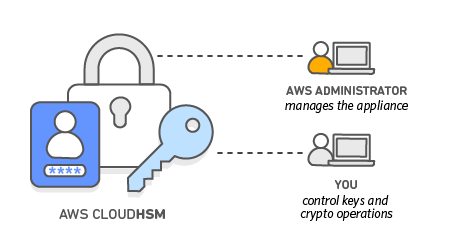
既然提到 HSM 了顺便提一句。
HSM 的核心其实就是 SP、tamper-proof NVRAM + embedded service。
而所有的这些 TEE 都有,而且也是一样的硬件信任根,那么基于 TEE 完全可以低成本地构建功能强大的 HSM。这也被称为 soft-HSM。
实际上 soft-HSM 必然成为构筑零信任基础设施中重要的一环,TEE-PKI、TEE-KMS 是整个零信任大厦的根基。
TPM 与 vTPM 的融合¶
前文提到 vTPM 和 intel TDX,讲到如今基于 TDX 的 vTPM TD 已经可以可信地解决 CVM 的度量问题。
但是其实还有一个问题没有解决,就是 host os 的度量问题。
vTPM 因为是软件模拟,而不是 TPM 的设备虚拟化,所以 host os 度量和 guest os 度量间仍然存在一个信任链的断裂口。
未来应该会有更多的硬件或软件上的进步来弥补这一鸿沟。 我们目前也有一些方案,不过目前就先不透露了。
OpenSource Firmware¶
基于硬件的 TEE 将硬件视为 RoT,但是这些硬件真实的可信度实际上是要打个问号的。
Intel 或 AMD 这样的厂商,只能用自己的商誉为其背书,而不能像远程认证这样通过更为逻辑严密的方式提供证明。
这一点过去的人们无条件的信任权威 CA 一样,然而事实终将证明没有任何由人控制的组织值得信赖。 我希望未来有一天,硬件设备制造商,也会有 CT Log 之于 CA 一样的透明度制度,为其提供第三方的监管和制约。
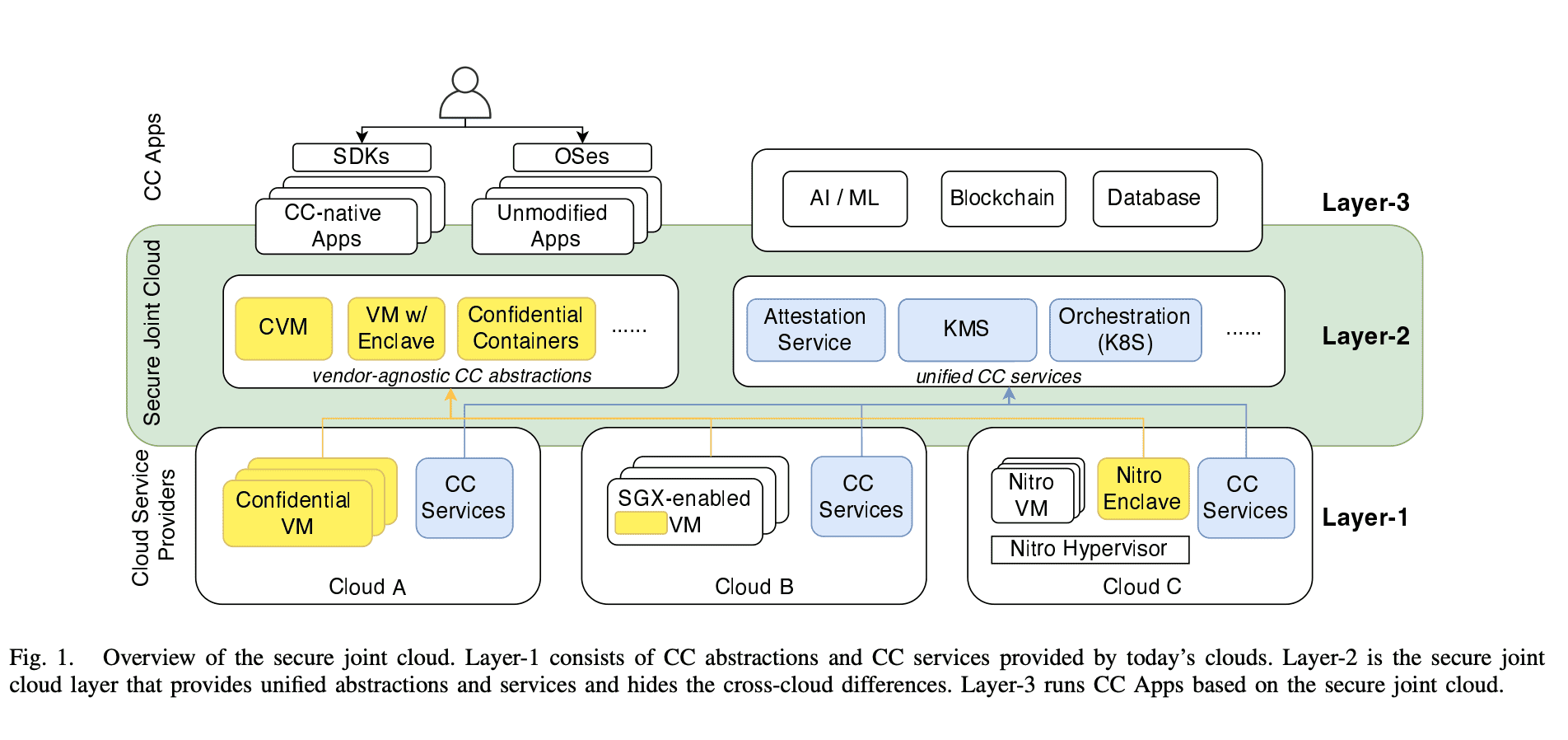
Secure Joint Cloud¶
Towards A Secure Joint Cloud With Confidential Computing - doi 10.1109/JCC56315.2022.00019
正如我们前面提到,所有的 TEE 都具备一些通用能力。
那么自然会想到,能不能采用一些通用的抽象,把所有的底层 TEE 统一起来,这种思路,可以成为 Secure Joint Cloud,实际上也是目前的一个热门发展方向。
谢谢
如有更多问题,可以通过邮箱 [email protected] 联系我