Golang Memory Model¶
本次分享会的目的是导读《Go Memory Model》这篇文档
先来一个灵魂拷问🧐
以前听说过 Memory Model 吗?
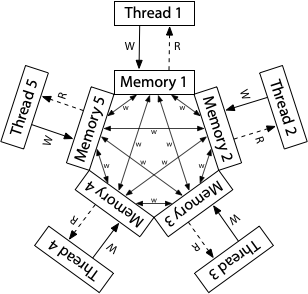
标准答案:没有全局时钟的系统
简而言之,两个独立发生的事件,不能通过一个全局时钟来确定先后顺序,这就是一个分布式系统。
什么情况下会导致没有全局时钟呢?这才是独立运算、通信延迟、blablablabla 那一堆
Partial Order¶
那如何在一个分布式系统中建立事件之间的顺序呢?
毕竟我们知道顺序是必要的,如果两个代码连运行的先后顺序都无法确定,这程序也没法写了。
专业点地说,我们需要在多节点中确定顺序一致性,使其表现得像是在一个节点上顺序执行。
这要从 1978 年的一篇论文《Time, Clocks, and the Ordering》说起(作者是 Lamport,就是发明 Paxos 那位)
论文我不细说了,简而言之,Lamport 提出,可以在分布式的节点之间,通过一些跨节点的事件来建立因果序,以此为基础,从而为系统中的其他事件进行排序。这种排序也被称为 partial/causal order。
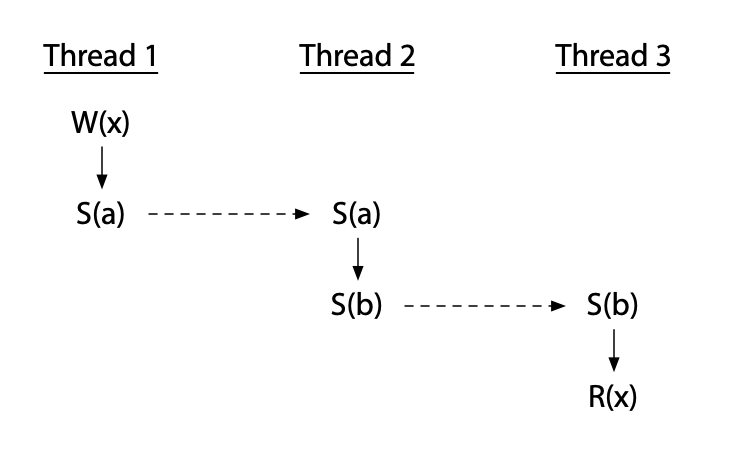
S 是跨界点的同步事件,这些事件在不同的节点上存在因果序(比如一边是读,另一边是写)。基于 S,可以为其他那些单节点内的事件确定 HAPPENS BEFORE 联系
W HAPPENS BEFORE S(a) HAPPENS BEFORE S(b) HAPPENS BEFORE R
题外话
偏序关系是分布式系统理论的基石,你可以看到分布式一系列的基础理论都是在此基础上提出的。
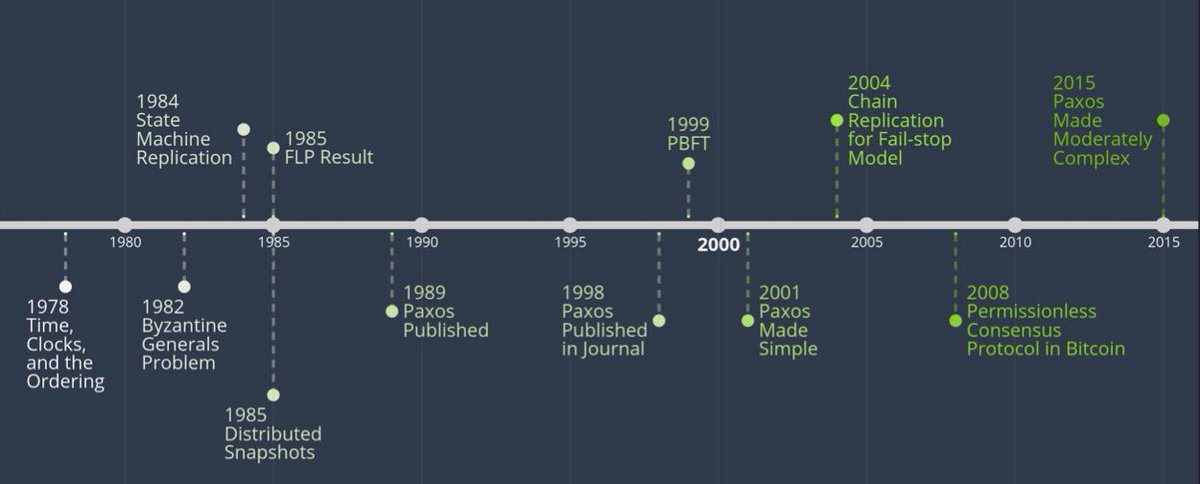
这个不展开了,以后 maybe 可以慢慢聊
DRF-SC 像是一份契约,只要你通过同步事件(Synchronization)在多线程间能唯一确认因果序,也就是符合 DRF-SC 规范,那么编译器和 CPU 就应该保证你的代码能够满足顺序一致性(sequential consistency)。
DRF-SC 的意义在于:
- 告诉编译器如何优化代码且不破坏一致性
- 告诉 CPU 如何执行代码且不破坏一致性
- 告诉程序员如何编写代码以符合 DRF-SC
那对于程序员而言,这个同步事件(Synchronization)究竟是什么?
其实很简单,比如一个跨线程共享的锁,lock/unlock 间不就有严格的顺序吗?这就构成了一个同步事件。
Memory Model¶
有了前面的基础知识后,现在我们就可以回答什么是 Memory Model 这个问题了:
Memory Model 就是多线程程序如何操作内存,如何进行同步的定义。不同的语言都有自己的 Memory Model
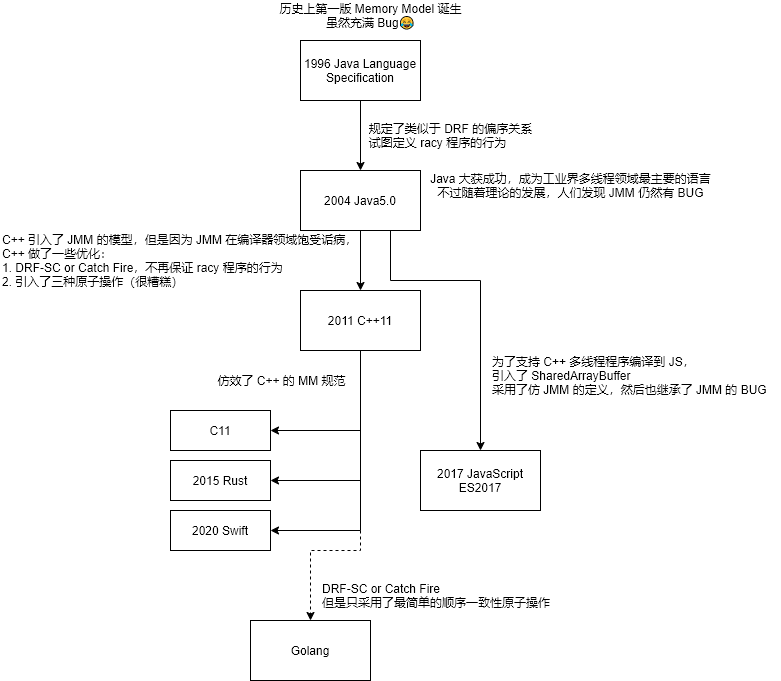
简而言之,有这么一条发展路径:
Java 是最早定义 MM 的语言,在早期的尝试中遭遇了一系列的失败。Java 的问题在于尝试定义 racy 程序的行为,这导致了编译器实现的巨大困难,以及事实上留存至今的 BUG。
C++ 第一个采取 DRF-SC or Catch Fire 策略,这一策略放弃了 racy 程序,只保证 DRF 程序的行为。
从目前的现状来看,所有试图定义 racy 程序行为的努力都尚未成功(Java 和 JS 迄今仍有 BUG),
而 Golang 也选择了 DRF-SC or Catch Fire 的道路。
值得强调的一点是,多线程程序的一致性是如此的复杂,事实上至今仍然没有一个被广泛承认的 Memory Model。
希望不远的未来能够出现一个……
顺带一提,前面提到 Java 和 EcmaScript 迄今的 Memory Model 都有 Bug。
这个有 Bug 不代表程序会出错,举个例子就是
var x = 0
func foo() {
x = 5
}
func main() {
go foo()
time.Sleep(5 * time.Second)
x = 3
fmt.Println(x)
}
这段代码存在 race,但实际上在运行中几乎绝对不会产生真正的 race。这就叫做有 bug,但是也不会出错😂
首先,介绍了需要 Memory Model 的原因:CPU 和编译器都会重排代码,且多线程读写相同的变量存在 race。
Memory Model 需要定义一个规范,让CPU和编译器知道该如何能在不破坏代码顺序一致性的情况下优化代码。
然后介绍了实现 DRF 的核心理念:
首先,定义一系列可以跨线程的同步事件(synchronization),
然后以这些事件为参照系,建立所有语句间的偏序关系(happens before)。
基于偏序关系去为代码排序,从而化解(或检测)对数据的 race。
第一章提到为多线程程序建立联系的关键参照系是同步事件(synchronization),第二章就是介绍 Golang 里有哪些同步事件。
- 初始化事件 Initialization
- p import q,那么 q 内的 init 函数 HAPPENS BEFORE p 内的任何代码
- main 函数 HAPPENS AFTER 所有的 init 函数
- 创建 Goroutine
- 声明创建 goroutine 的语句(
go foo())HAPPENS BEFORE foo 内的任何代码
- 声明创建 goroutine 的语句(
- 销毁 Goroutine
- goroutine 内的 defer 不是同步操作,不保证任何顺序
- Channel 交互
- channel 是 go 最主要也是最推荐的同步操作,发送 HAPPENS BEFORE 接收
- 关闭 channel HAPPENS BEFORE 接收到默认空值
- 某次接收 HAPPENS BEFORE 下一次接收
- sync 包内的 Mutex 和 RWMutex
- 对于同一个锁,上一次的 Unlock HAPPENS BEFORE 下一次的 Lock
- sync.Once
- 对于
once.Do(f),对 f 的调用 HAPPENS BEFORE 所有once.Do(f)的返回
- 对于
这些就是 Go 最重要的同步事件,编译器基于此建立整个程序的偏序关系,然后为所有的语句排序。如果发现有两个处于同样偏序的命令试图操作同一个内存数据,那么就会导致 race。
作为程序员,简而言之有一条最简单的心得:
调试代码和测试的时候一定要启动 -race 命令!!!
(前面都没听不要紧,这句话一定要记住)
这次只是非常简单地介绍了 Memory Model 的大体概念,和 Golang 的实践。
实际上 Memory Model 是一个非常大也非常有趣的题材,涉及到 CPU 体系架构、编译原理、形式化验证,甚至涉及到分布式系统理论!
这一理论在近年发展也很迅猛,算是计算机基础领域为数不多的还有生命力的理论(毕竟 CPU、分布式等大部分理论在上个世纪就已经构筑完成了。)