LLM RAG¶
https://arxiv.org/abs/2312.10997
《Retrieval-Augmented Generation for Large Language Models: A Survey》这篇论文介绍了 RAG 技术的发展。
本文尝试对其关键要点进行一些简单的介绍。

Why Need RAG, LLM 面临的问题¶
在介绍 RAG 是什么以前,先介绍了 LLM 目前所面临的问题
数据集落后¶
高昂的预训练成本带来一个最直接的问题就是:模型更新缓慢。 GPT-3.5 的数据集时间为 September 2021。
而且数据集的更新成本不仅仅是训练,还有数据集的收集和清洗,这都进一步降低了模型更新的频率。
Training GPT-3 would cost over $4.6M using a Tesla V100 cloud instance.
hallucination 幻觉¶
有一种观点认为 LLM 是一种高效的有损信息压缩算法,它的信息解压缩过程依赖于用户 prompt。
这使得 LLM 的答复质量非常容易受到用户 prompt 的干扰。

Transparency 透明性¶
LLM 给出的回答完全是黑盒,根本不知道来自哪,自然也就难以查证。
RAG¶
前文介绍过,RAG 就是为 LLM 引入外部的数据源, 根据 LLM 对 parameter 的依赖程度,可以再分为三类:
- fully parameterized model:只依赖预训练数据。也称为 ROG(Retrieval-Off Generation)
- RAG:hybrid
- RCG:完全依赖推理时的外部信息
可以看出 RAG, Retrieval-Augmented Generation 是一种结合预训练数据和外部数据源的混合增强方法。
或者更通俗的理解为:在直接将用户 query 交给模型以前,先进行一轮信息检索,完善输入信息。
RAG Vs. Fine-Tunning¶
RAG 和 fine-tuning 都是可以提高 LLM 模型性能的方法,两者的应用场景存在一些差别:
- RAG 适合少量垂直领域的精确信息,不适合开放式的大量数据
- fine-tuning 适合大量数据
需要注意的是,fine-tuning 和 pre-traning 的区别在于:
fine-tuning 不适合让 LLM 学习新知识,而是适合让 LLM 强化某个已知知识。
可以认为 fine-tuning 是复习,RAG 是考试时的小抄。

fine-tuning 和 RAG 并不矛盾,两者契合可以发挥出更大的作用


RAG's Evolution¶
介绍 RAG 技术和工作流的进化
Naive RAG¶
最简单的 RAG,就是顾名思义的执行三个步骤:
Retrieval: 根据 prompt 抓取外部数据Augmented: 使用外部数据增强 promptGeneration: 把增强后的 prompt 交给 LLM,生成 predict/answer
embeddings¶
Naive 处理资料集的方式也是单一的:
- 首先,全部转换为文字(text)
- 对文字进行切块(chunk)
- 把每一个 chunk 交给 embeddings-model,计算词向量(word vector)
- 将词向量和 chunk 存储向量数据库
embeddings 就是基于 LLM 将一个语句转化为一个高维向量,切分资料的 chunk_size 是一个关键参数

Retrieval¶
执行类似步骤:
- 将 prompt 交给 embeddings-model,计算词向量
- 在向量数据库中执行 ANN 查询,获取 K 个最近似结果
注:Approximate Nearest Neighbours (ANN) 和精确计算距离的 KNN 不同,ANN 适用于高维空间的近似计算。
Augmented¶
将获取到的资料按照某个模板,和 prompt 进行拼接,得到最终 prompt
Generation¶
将最终 prompt 交给 LLM,得到回答。
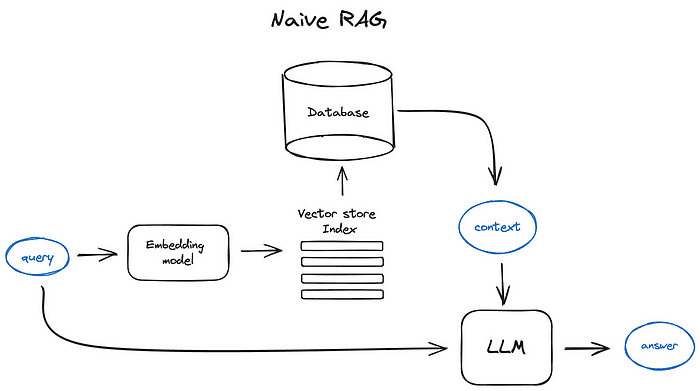
一个简单的结合向量数据库实现 prompt 增强的例子:

向量化的问题¶
可以看出数据的检索完全依赖于向量化所产生的词向量。
when an embedding model calculates the vector representation of a sentence, it does so based on the similarity of the sentence to the pre-trained data
而 embedding model 在计算一个语句的向量时,需要基于 pre-training 的数据来理解输入的语句。如果输入的语句和预训练数据集的差异特别大,会导致结果出现很大偏差。
基于词向量相似性搜索的方案,precision 和 recall 都很低。就是查询的数据不一定有用,有用的数据不一定被查询到。
Ps. precision 度量结果数据中的阳性率。recall 度量所有阳性被找到的概率。都是越高越好。
Advanced RAG¶
Advanced RAG 在 Naive 的基础上增加了 pre-retrieval 和 post-retrieval 两个方法。
工作流变为:
- pre-retrieval process
- embeddings
- post-retrieval process

Pre-retrieval Process¶
在 embeddings 以前,对数据进行清洗和规整,可以分为 5 个步骤:
Enhancing Data Granularity: 对数据内容进行修订和简化,确保数据源的正确性和可读性Optimizing Index Structures: 优化数据索引,引入图数据库、多级索引等结构GraphDB: 可以用来建立知识图谱,进行关联查询Hierarchical Indices: 索引和查询是两类不同的任务,可以使用不同的 index
Adding Medadata Information: 为切块后的数据增加 metadata,标记数据来源Alignment Optimization: 可以为每一个 chunk 生成一个假设性提问,然后将这个问题本身也嵌合到 chunk 中Hypotherical Question和用户 query 间具有更强的语意相关性,可以提高检索的关联度。
Mixed Retrieval: 混合使用多种检索技术,而不仅仅是词向量搜索。- 也称为 hybrid/fusion/mixed/ensemble retrieval

Embedding¶
对 embeddings 过程中所使用的 embedding-model 也进行改进
- Fine-tunning Embedding: 可以将领域知识预先通过 fine-tuning 内嵌到模型中
- Dynamic Embedding: 在 embeddings 时,不要仅针对关键词(static),而是要联合上下文一起(dynamic)。
Post-Retrieval Process¶
在完成资料查询,提交给 LLM 前,继续对收集到的资料进行优化
- ReRank: 根据关联度进行打分和重排序
- Prompt Compression: 无关输入对 LLM 的性能有负面影响。压缩不相关信息,强调关键信息,减少总长度
RAG Pipeline Optimization¶
一些通用的 RAG 检索资料优化办法
Hybrid Search: 前面提到过的混合检索Recursive Retrieval And Query Engine: 多阶段检索,先检索一批小 chunk,再根据小 chunk 去检索大 chunk- chunk size 和 user query 长度接近时,可能会提高准确性
Sentence Window Retrieval: 检索到小 chunk,然后返回 surrounding context 的大 chunkParent-Child Chunks Retrieval: 每个小 chunk 都指向一个或多个更详细的大 chunk,如果有多个大 chunk 被引用,则使用这个大 chunk 替换小 chunk。
StepBack-prompt: 一种 prompt-engineering,可以显著提高推理密集型任务的性能。让 LLM 更关注抽象概念Subqueries: 根据语意拆分为多个小查询HyDE: 先让 LLM 回答一次,然后根据 LLM 的回答再去搜索相关资料。但如果 LLM 对相关话题不熟悉,反而会加重幻觉。


Modular RAG¶
这是作者提到的 RAG 的最终进化形态。不过其实所使用的技术都是前面 naive 和 advanced 里提到过的。
最重要的改变更多是架构设计上的,将单一的命令式流水线(pipeline),变成了响应式的动态调度(adaptive/routing)。
所有前面提到过的功能都被封装为了功能模块,根据任务类型进行动态组合和调度。

Retriever¶
在 Modular RAG 中,Retriever 负责对外部数据源进行预处理和查询。
Fine-tuning Embedding Models¶
embedding 是 RAG 的核心,为了让 embedding model 能够更好地理解垂直领域信息,可以对 embedding model 进行 fine-tuning。
Ps. OpenAI 目前尚不支持该功能

Prompt Engineering¶

Multi Query Retriever / Sub Question Query Engine¶

Query Embedding Transformation¶
query rewrite 是粗粒度的,query 的 embedding 应该是细粒度的。
query 最终也需要被 embedding 然后再去搜索外部资料,处理 query 的 embedding model 也可以被 fine-tuning,以使其可以更好的匹配特定任务,尤其是使其可以更好的关联到结构化的数据
Aligning Retriever's Output and LLM's Preference¶
单纯的计算 retriever 的 hit rate(正确性)是不够的,因为可能查找的资料并不是 LLM 所需要的。 相比单纯的信息正确,LLM 更偏好于可读性更好的资料。
所以 retriever 还需要对齐(alignment),才能真正提高 RAG 的性能。
Generator¶
Generator 负责将 retriever 抓取的资料转化为更好的格式,喂给 LLM
Post-Retrieval Processing¶
retriever 抓取的资料可能过长或存在冗余。在 retriever 后,提交给 LLM 前,增加一步做数据清洗的 post-retrieval 步骤。
post-retrieval 的核心目标:信息压缩和结果重排(rerank)。
信息压缩的必要性:降低噪音,减少长度,增强 LLM 生成效率。(冗余信息会极大的干扰 LLM 的生成质量)
Rerank¶
RAG 里的 context 不是越多越好,实际上添加的上下文越多,LLM 的性能指标反而可能会降低。
Catastrophic Forgetting: LLM 学习新知识后会遗忘旧知识,导致回归性能降级。- 此外 LLM 的
In Context Learning (ICL)是位置相关的,越靠前效果越好。
rerank 可以改善 CF,通过将最相关的信息放在最前面,然后限制总的信息量。 我理解是,提供的新信息越少,对旧指标的干扰也就越少。
Augmentation in RAG¶
RAG 对 LLM 的提升是全面的,可以从三个维度来理解 RAG:
- Stages: RAG 可以应用于 LLM 生命周期的全部三个阶段:pre-training、fine-tuning、inference
- Data: 可以对数据进行增强
- Process: RAG 的具体实操方法
RAG 概念概览¶


Pre-training Stage¶
在 Pre-training 阶段就引入 RAG,对预训练数据集进行增强。
优点:基于 RAG 的数据增强,比从头去重新准备预训练数据集要更简单。
缺点:和预训练一样的缺点,更新缓慢,更新成本高。
Fine-tunning State¶
对于垂直领域,针对 LLM 和 retriever 都进行 fine-tuning,可以提高性能。
fine-tuning 的缺点:需要结构化的训练数据,需要的计算资源远大于推理。
对数据源进行增强¶
基于知识图谱的结构化数据,可以在数据检索时提供更为关联的信息。
LLM Generated Content RAG¶
外部输入的新知识有时候会对 LLM 的性能带来负影响,所以有一条 RAG 的研究道路是探索深入挖掘 LLM 的内生知识。
SKR 让 LLM 区分已知和未知信息,只要求 retriever 获取未知信息,使用内置信息回答已知问题。
Augmentation Process¶
本节讨论 RAG 操作流程的优化。
单步 RAG 可能会因为信息冗余使得 LLM 抓不住重点(lost in the middle)。 此外,也让 LLM 无法进行深入的多步推理。
可以设计一个逻辑 loop: retriever - generator。通过多轮循环,以取得更好的效果。 (Recursive retrieval and multi-hop retrieval)
Iterative Retrieval¶
利用外部数据增强推理 & 利用推理增强数据抓取,不断循环迭代
Adaptive Retrieval¶
也叫做 query routing。实际上就是利用 tools/agents/function call 的功能,让 LLM 可以自行根据 context 调用 retriever 抓取外部数据源。
function calling / tools¶
function calling 是一个多轮交互过程,简而言之就是让 LLM 可以主动问问题,然后你将答案融合到原始 query 后再重新交给 LLM。


RAG Evaluation¶
Evaluation Methods¶
有两种评估方式,其实和我们惯常的测试方法论也是一样的
- Independent Evaluation: 对各个流程/模块进行分别测试,可以理解为单元测试
- End-to-End Evaluation: 顾名思义,模仿用户行为,直接就最终接口进行测试
E2E 测试又可分为 unlabeled 和 labeled。我的理解是,labeled 应该是偏向于人工校验,需要提供标准答案,然后计算 EM 等指标。unlabeled 偏向于自动测试,可以使用一些标准方法计算得分。
Retrieval Metrics¶
Hit Rate (HR): 检索到相关资料的概率Recall: 所有应该被检索的文档里,被正确检索出来的比例Precesion: 检索出来的文档里,相关文档的比率Mean Reciprocal Rank (MRR): rerank 的指标,度量 retriever 返回的最优信息是否出现在了最前列Mean Average Precision (mAP): 也称为mAP@K,度量第 K 个正确答案的位置。可以理解为 MRR 的复数版。Normalized Discounted Cumulative Gain (NDCG): 度量整体的 rerank 质量Exact Match (EM): 查询到的资料里,包含正确答案的概率F1 Score: 就是 recall 和 precision 的调和平均数:Semantic Answer Similarity (SAS): 比较正确答案和 LLM 回复(predict)间的语意相似度。
Key abilities¶
能够支撑 RAG 的底层 LLM 所应该具备的四个基础能力:
- Noise Robustness: 能够分辨噪音
- Negative Rejection: 信息不足时应该拒绝回答
- Information Integration: 能够整合杂乱的信息
- Counterfactual Robustness:能够分辨 retrieval 提供的信息中存在的事实错误
明显在做梦😂,现实是通用大模型的 hallucination 非常显著
Vertical Optimization¶
垂直优化,和水平扩容相对,一般指增强自身的能力,而不是依靠外部扩展,此处指增强 LLM 自身的能力。
包括更大的 context,更稳定的回答能力。目前的 LLM 极易受到参考信息中的错误和无关信息的干扰。
RAG 和 Fine-tuning 更深入地互相协调也是一个重要的优化方向。
最后就是 RAG 的工程实践,包括性能提升和安全性。

Security¶
简单提一下 RAG 安全
ACL¶
基于 RAG 的外部数据访问,可以使用更传统的数据集 ACL 来对用户、数据进行细粒度的访问,这在安全性上能够显著的强于对预训练数据集的“徒劳”保护。
Prompt Injection¶
Prompt Injection 是目前 RAG 无法绕开之痛,甚至可以说 Prompt Injection 是目前阻碍所有接收用户 query 的 LLM 走向成熟产品之路上最大的阻碍。
本文所参考的论文中没有论及相关信息,下次再另做一次关于 LLM 安全的分享。
RAG cannot avoid hallucination¶

但是 RCG 并不仅仅是给 RAG 更多的数据,而是对底层 LLM 的设计方向存在一些根本性的变化:
- 小型定制化模型可以取代大型模型,在 RCG 领域取得同等的性能
- 对未知数据(unseen data)的学习和理解能力
- RCG 追求的是 100% 准确性和透明性,完全消除幻觉(learn and abstract the schema as an emergent capability)
- LLM 不仅仅能比对信息,还能够具有抽象范式的理解能力
LLM 的研究重点,从内嵌更多的数据,转变为对数据抽象模式的认知能力。

pre-training 不再是让 LLM 记忆信息,而是让其学习抽象模式

RCG 被认为是 toB 领域 LLM 的研究重点,因为只有 RCG 能在垂直领域提供企业所需的精确性和可追溯性。
具体的一些内容我现在也还不懂,等日后也许会令做一期分享。